

Now that re:Invent 2022 is officially over, let's go over the exciting new services and features launched from a Serverless developer perspective.
The Keynote

The Serverless "vibe" started at the keynote.
Dr. Werner Vogels was wearing a t-shirt with a Lambda logo.
Dr. Werner Vogels, Amazon.com VP and CTO, talks about the benefits of building asynchronous, loosely coupled systems and how event-driven architecture enables global scale. He then explains how the cloud is enabling customers to build more immersive experiences using 3D and how simulation is empowering customers to experiment and innovate in new ways. - AWS https://www.youtube.com/watch?v=RfvL_423a-I
Let's review the most exciting new services and features for us developers.
Step Functions Distributed Map
A Serverless Solution for Large-Scale Parallel Data Processing
Have you ever wanted to process massive S3 objects quickly using 10,000 concurrent lambda functions? Well, now you can.
The existing map state is limited to 40 parallel iterations at a time.
However, the new Step Functions distributed map flow supports a maximum concurrency of up to 10,000 executions in parallel. You can process data by composing any service API supported by Step Functions, but typically, you invoke Lambda functions to process the data.
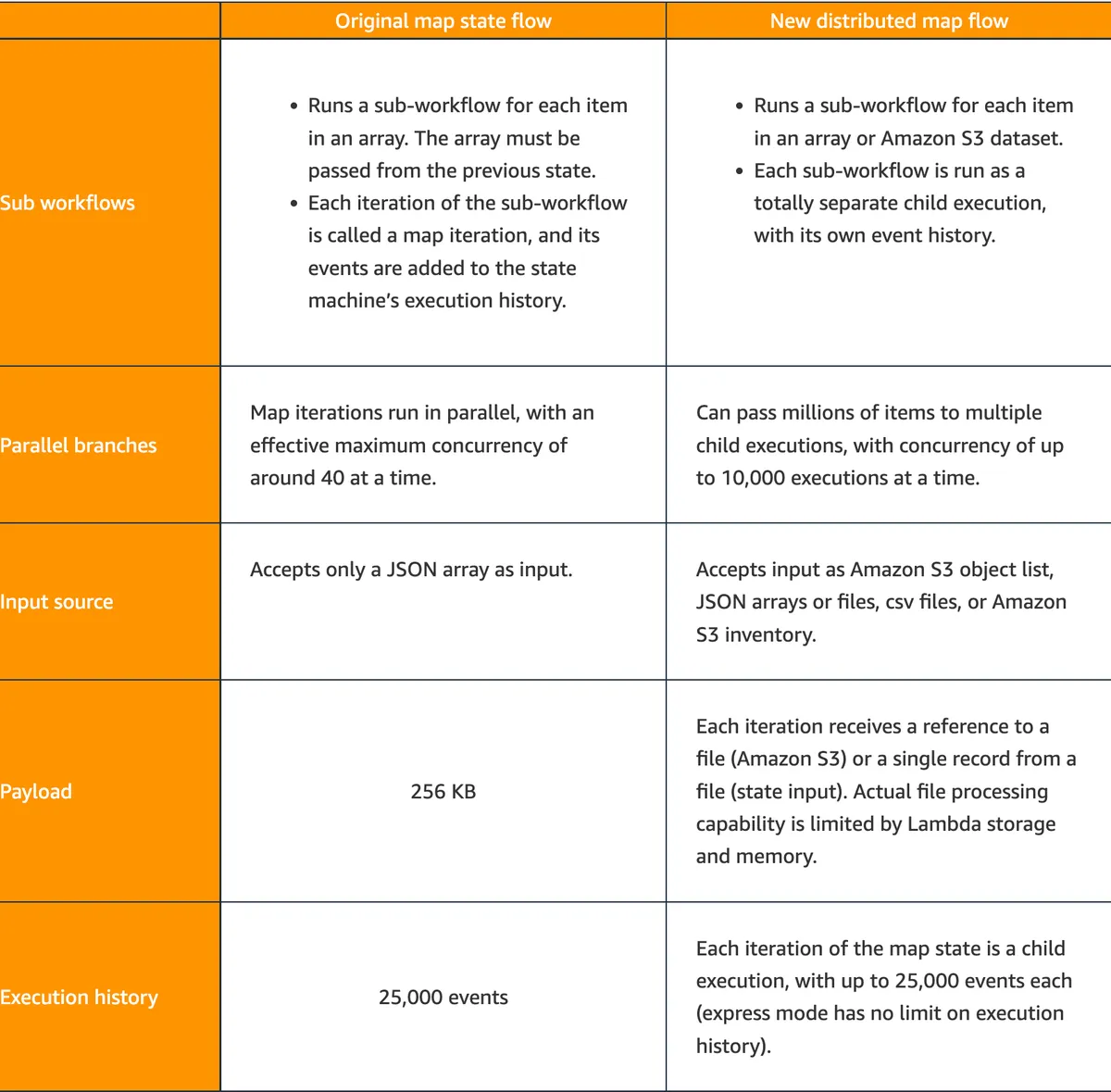
For the processing itself, I'd suggest the brand new AWS Lambda Powertools streaming utility for Python that fits like a glove.
You can process huge files stored on S3 line by line in your lambda function code without loading the file to the lambda memory or file system.

Usage Example:
https://docs.aws.amazon.com/powertools/python/latest/utilities/batch/
Amazon EventBridge Pipes
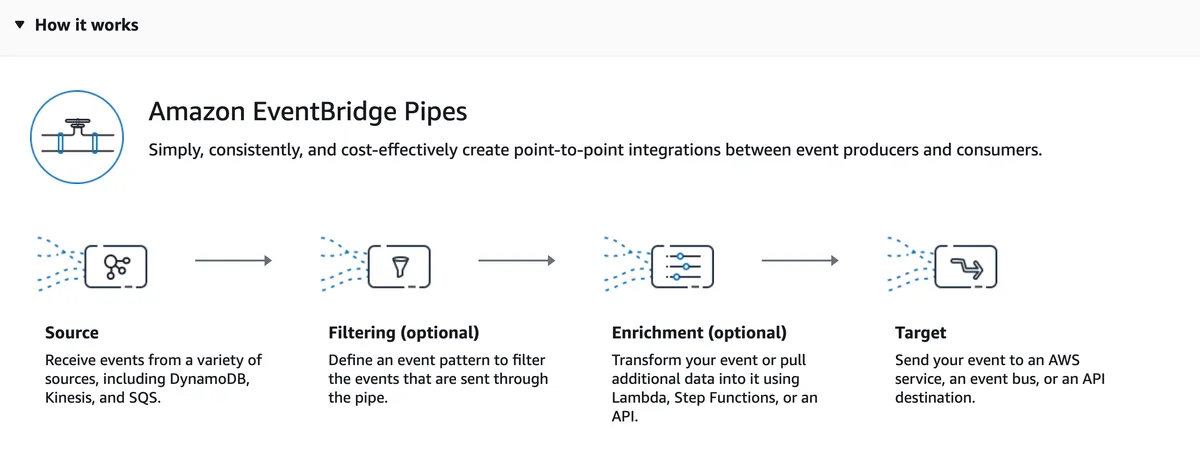
It's a simple, consistent, and cost-effective way to create point-to-point integrations between event producers and consumers, removing the need to write undifferentiated glue code. Amazon EventBridge Pipes bring the most popular features of Amazon EventBridge Event Bus, such as event filtering, integration with more than 14 AWS services, and automatic delivery retries.
Building an asynchronous event-driven system has become even easier and with less code!
Now it's even easier to create integration between producers and consumers while taking care of input filters, data enrichment and automatic retires of failures.
The source services include Kinesis, SQS, DynamoDB, Amazon MQ, Apache MSK, and self-managed Kafka and the target sources are even more extensive with 14 supported services, including API GW, SQS, EventBridge, and others.
Read more at:
Lambda SnapStart
This feature delivers up to 10x faster function startup times for latency-sensitive Java applications at no extra cost, and with minimal or no code changes.
This is one pretty big for you Java folk.
A new and improved way to reduce cold starts instead of enabling the pricier lambda provisioned concurrency.
AWS Lambda takes an encrypted snapshot of the function's memory and disk right after it initializes and before it handles the invocation input and context.
Now imagine that each lambda invocation starts from this point each time it is freshly invoked, thus reducing cold start dramatically without any extra cost.
Lambda takes a Firecracker microVM snapshot of the memory and disk state of the initialized execution environment, encrypts the snapshot, and caches it for low-latency access. When your application starts up and scales to handle traffic, Lambda resumes new execution environments from the cached snapshot instead of initializing them from scratch, improving startup performance.
https://aws.amazon.com/blogs/compute/starting-up-faster-with-aws-lambda-snapstart/
Amazon OpenSearch Serverless (Preview)
https://aws.amazon.com/opensearch-service/features/serverless/
Great news for OpenSearch users!
It is now more straightforward and cost-effective than ever to add text-based search to your application.
Amazon OpenSearch Serverless is the managed version of the service which means that scaling up and down the OpenSearch cluster is now a problem of the past.
In addition, cluster scaling optimization means less cost in the long run.
Amazon Inspector & Lambda
You can never have too much security.
Amazon Inspector Now Scans AWS Lambda functions and lambda layers for vulnerabilities.
Your lambda function code relies on many open-source libraries of which you are only sometimes aware. Somewhere down the chain, a vulnerability can expose your code to attacks.
Amazon Inspector will automatically scan your entire account for the Lambda function and layers (currently being used) and alert you in case of a security issue in its dashboard.
It’s a great security feature that until now, I had to rely on 3rd party solutions for scanning my function’s dependencies.
Amazon CodeCatalyst (Preview)
This service aims to improve the onboarding experience, i.e., internal developer onboarding of a new SaaS service from the developer to the product manager.
Gone are the days of trying to install a developer environment machine for days or building a service boilerplate for weeks.
Amazon CodeCatalyst can be viewed as a self-service developer platform for SaaS services.
As an architect in a platform engineering group, we have spent years trying to build the perfect Serverless self-service experience. CodeCatalyst aims to make it easier.
You start with a "blueprint" that creates a service (as defined by your company) with its resources deployed on AWS, CI/CD pipeline, and a local development environment.
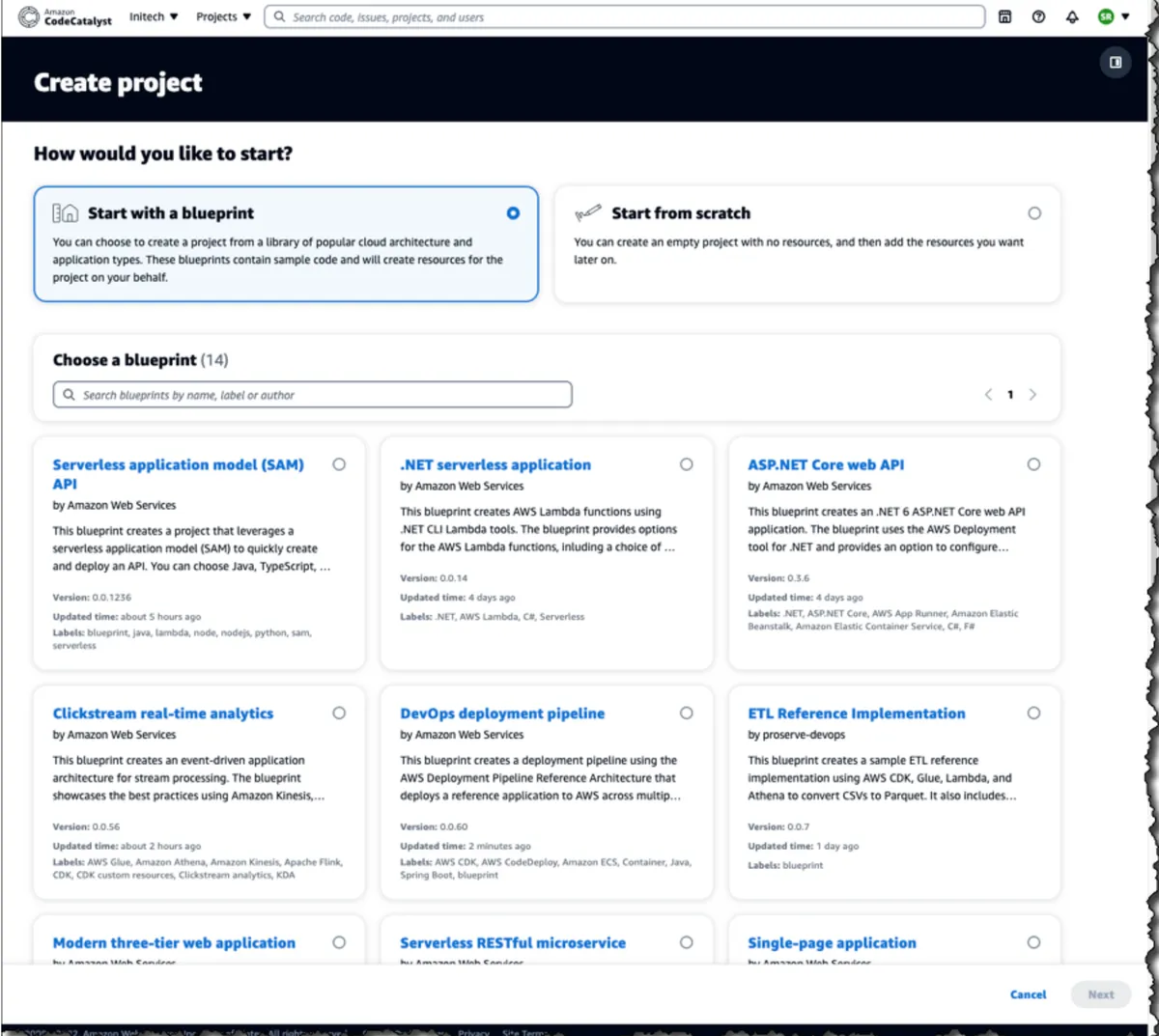
There's even AWS Cloud9 support for a cloud-based development environment.
Imagine spending zero time installing and setting up a dev environment; you spin up your machine from the company baseline developer image and start developing your new service.
Another interesting aspect of this service is the product management aspect support - ticketing system, issue monitoring activities board.
AWS Application Composer (Preview)
As a Serverless architect, I use tools like Lucid Chart and Draw.io to create a diagram that describes the high-level design of my applications.
Then, the developers take my diagram, turn it into an AWS CDK stack code with business logic code, and deploy it into a reality.
AWS Application Composer allows me to interactively create Serverless application diagrams and export them as SAM templates that can be deployed immediately.
That's quite impressive!
One could chart complete systems with this tool and deploy them immediately without writing a single line of CloudFormation configuration.
While I don't suggest you ditch your IDE just yet, this service is a significant step towards shortening the Serverless architecture adoption time and creating new Serverless services quickly.
It's an excellent tool for Serverless beginners but also for those starting a new service who want to quickly deploy a POC to verify the design. Once verified, the output can be passed to the development team for final touches and writing the business logic tests.
One caveat - it does not support AWS CDK, Pulumi or Terraform yet. Please use the feedback button on the bottom left in the AWS Application Composer console and ask for your chosen IAC framework support.
https://aws.amazon.com/application-composer/
Amazon Security Lake (Preview)
Amazon‘s version of a modern data lake for an organization's security logs in the Open Cybersecurity Schema Framework (OCSF) open format.
Amazon Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built data lake stored in your account. With Security Lake, you can get a more complete understanding of your security data across your entire organization
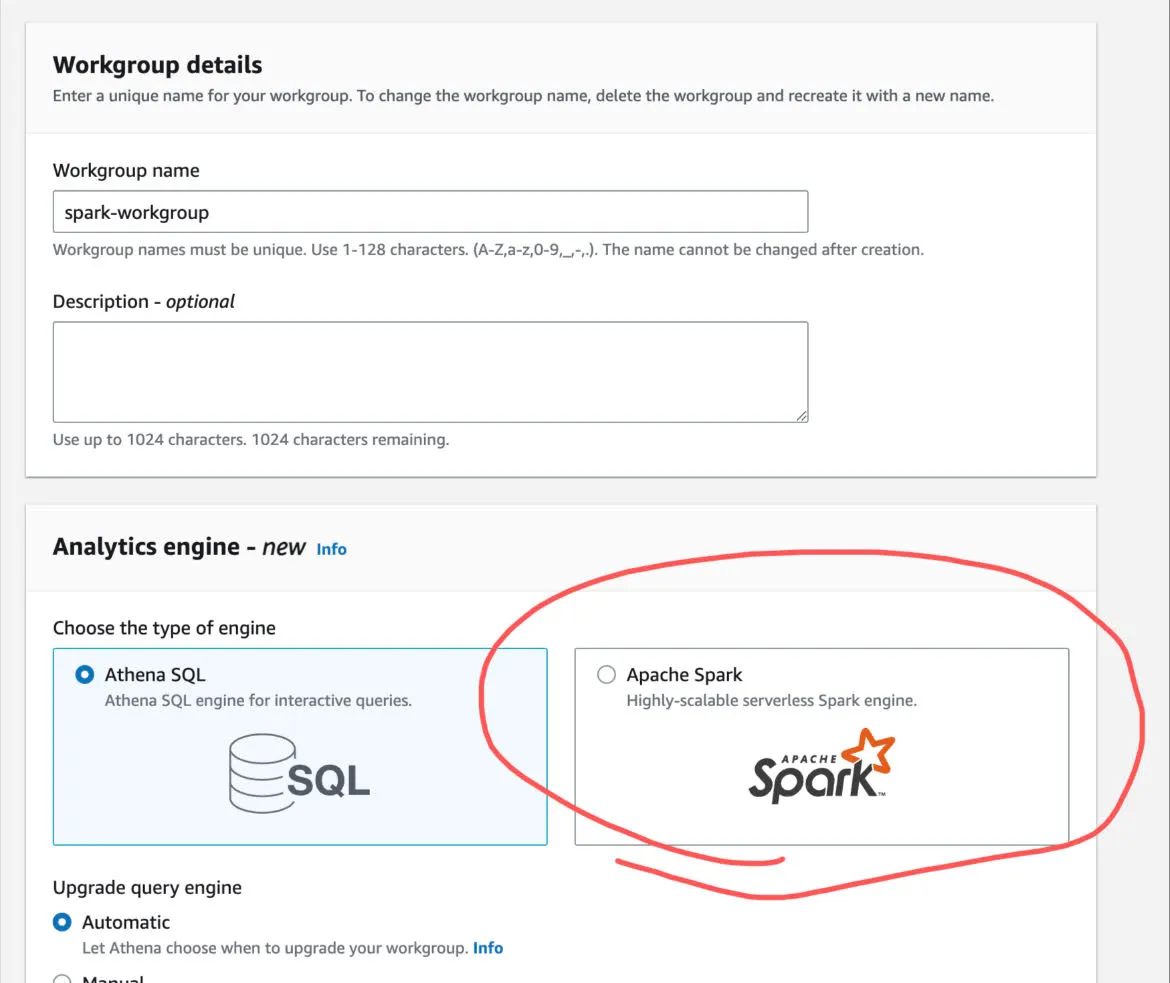
Amazon Athena for Apache Spark
Big news for the data engineers among us, you get a new Serverless buddy!
Get started with interactive analytics using Amazon Athena for Apache Spark in under a second to analyze petabytes of data. Interactive Spark applications start instantly and run faster with our optimized Spark runtime, so you spend more time on insights, not waiting for results.
Amazon Athena now adds a new analytics engine - Apache Spark in a Serverless flavor.
Being Serverless, you don't worry about managing it, upgrading its version, or scaling it up and down. You can focus on your computation logic.
Run Spark applications cost-effectively, without provisioning and managing resources. Build Spark applications without worrying about Spark configurations or version upgrades.
https://press.aboutamazon.com/2022/11/aws-announces-five-new-database-and-analytics-capabilities
Thank you Igal Drayerman for sharing this with me.


