

What is AWS CDK?
AWS CDK lets you build reliable, scalable, cost-effective applications in the cloud with the considerable expressive power of a programming language
I think AWS CDK revolutionized how we create resources in the cloud.
AWS CDK enables developers to write infrastructure as code and feel at home.
It is such a flexible and powerful tool that it’s easy to make mistakes.
Some mistakes prove to be very costly.
A couple of weeks ago, I asked developers on LinkedIn and Twitter why they are not using AWS CDK (multi-cloud aside) and received plenty of responses and concerns; Thank you for sharing your experiences!
I see myself as an AWS CDK advocate; I’ve lectured about CDK internally at my place of work, hosted a webinar, and gave a talk at the first AWS CDK Day 2020:
So I decided that the best way to address those concerns and convert people over to CDK was to:
- Write my take on a CDK best practices guide gathered from almost three years of developing with CDK.
- Provide a working CDK template project that implements these practices which can be found at the AWS Lambda Handler Cookbook repository.
AWS CDK Best Practices
These guidelines expand the official AWS CDK best practices.
Please note that this blog post assumes you have basic AWS CDK knowledge and understand the concepts of stack and constructs.
These guidelines are split into several categories:
- Project Structure and stack guidelines
- Constructs guidelines
- CI/CD guidelines
- Resiliency & Security
- General development tips
Prefer video? Watch the video version:
Project Structure and Stack Guidelines
These guidelines discuss a recommended project structure.
One Repository, One Application, One stack
“Every application starts with a single stack in a single repository” — AWS CDK best practices guide
According to the official AWS CDK best practices, your code repository should hold no more than one CDK application, one stack with one or many constructs maintained by one team.
I agree with this practice.
Adding more stacks and applications to the repository will increase deployment time and blast radius in case of errors.
Instead of multiple stacks, use numerous constructs.
However, how do you know when to split a stack into multiple stacks?
My rule of thumb is to split when:
- The new stack is a different service or microservice with additional requirements or deployment strategies (deploy to multiple regions etc.).
- A different team will maintain the new stack.
- The new stack has a different business domain.
- Deployment has become too long or too complex in the stack. Break the stack into microservices spreading several repositories. Dependency/contract between the microservices will be defined with REST API/SQS/EventBridge/SNS etc.
AWS SaaS Service Repository Structure
AWS CDK code and service AWS Lambda handler reside in the same repository but in different folders as separated python modules.
The project is constructed from two inner projects: infrastructure as code CDK project and the service code (AWS Lambda handler code with tests).
These two inner projects are separated to reduce the blast radius in case of errors, and improve the ease of testability of each project.
Since I develop Serverless services, the example describes a Serverless project. However, the structure remains the the same for any non Serverless services.
The main project folders are:
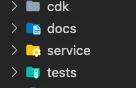
- CDK folder: under ‘cdk’ folder. A CDK app deploys a stack that is consisted of one or more CDK constructs. CDK constructs contain AWS resources and their connections/relations. Read more about the CDK project details here and here.
- Docs folder: GitHub pages service documentation folder (optional).
- Service folder: AWS Lambda project files: handler, input/output schemas, and utility folder. Each handler has its own schemas folder. The utility folder stored shared code across multiple handlers.
- Tests folder: unit/integration and E2E tests. By separating the service code from the infra, running the tests locally in the IDE is more straightforward.
You can find my Serverless template project on GitHub and the accompanying blog post.
Create Template Projects
To speed up Serverless adoption and CDK usage, you can create a template project that provides a new service and team with a working CDK deployable project with a functional pipeline and AWS Lambda handlers that contain all the best practices.
As an Architect in a cloud platform group, we understood it’s important to share constructs and provide guides to CDK how-to, including a template project.
You can find my Serverless template project on GitHub and the accompanying blog post.
Constructs Guidelines
This section contains best practices for developing constructs.
Stack Composition
Use constructs to model your application’s infrastructure domains.
Strive to keep stack-defined non-constructs resources to a minimum.
If two constructs have the same resource dependency, either:
- Put the resource in a new construct and supply it as an input parameter to both
- Decide which construct has the right to “own” it and create it internally. Provide it as an input parameter to the other construct.
Business Domain-Driven Constructs
I don’t think there’s a right or wrong approach to picking resources into constructs as long as it makes sense to you and you can find resources and configurations easily.
However, I believe choosing a business domain-driven approach to selecting which resources belong together in a construct makes sense the most.
It’s easier to find resources and understand their connections simply by looking at the service architecture diagram. It’s also easier to share design patterns across teams in organizations that might require the same architecture.
Let’s assume I have a Serverless ‘booking’ service containing two business domains:
- Provide REST API for CRUD actions for a booking system to be used used by customers.
- Send booking data across several internal services (share and send booking information in an async service-to-service method.
Let’s assume I have designed the following architecture:
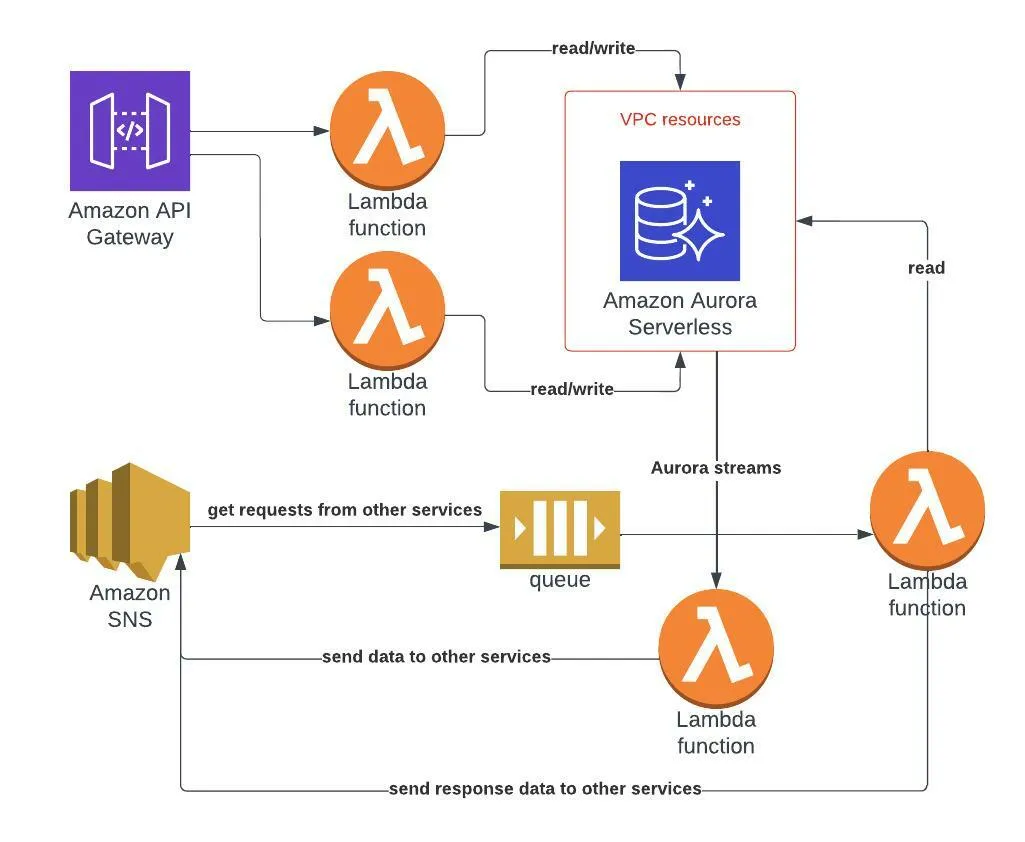
- API GW with CRUD AWS Lambda functions.
- AWS Aurora database used by the CRUD functions for both read/write queries.
- AWS Aurora streams trigger an AWS Lambda function that send data via an AWS SNS topic to other external services.
- AWS SNS — a cross services central pub/sub implementation. It allows both the ‘booking’ service and the external services to send messages to each other via the booking topic.
- AWS SQS subscribed to the SNS topic and an AWS Lambda function destination of the SQS. This Lambda function gets a request event from the SNS and, queries the Aurora database and send a response via the SNS.
Note: AWS Aurora database is accessed by the CRUD API and the SQS/streams Lambda functions. However, CRUD usage is read/write while the SQS/streams lambdas is read-only.
How do we create the constructs?
I’d model the service into two business domain constructs: CRUD and Messaging.
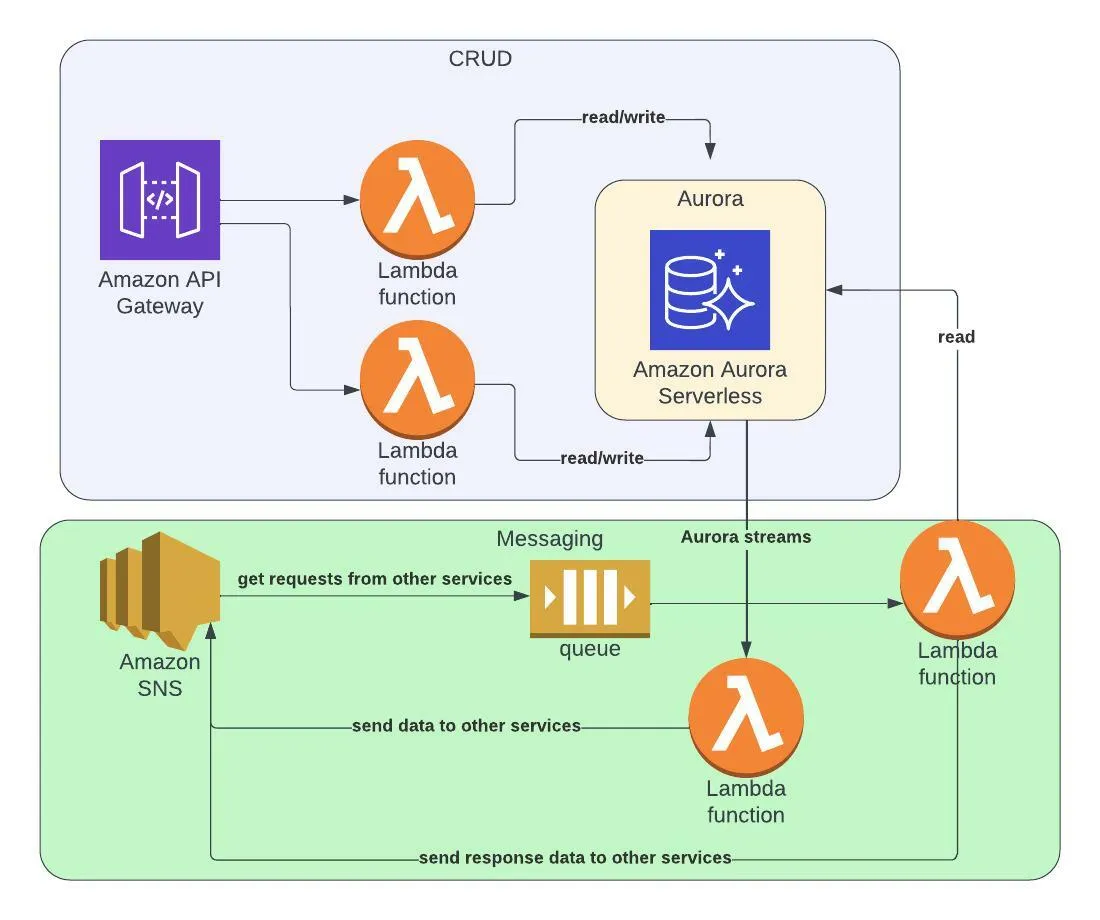
The CRUD construct will create an instance the following resources:
- AWS Lambda functions and their roles.
- Aurora construct — AWS Aurora is relatively complex to define in CDK (VPC, Databases, permissions, etc.) and should be handled in its own construct instantiated inside the CRUD construct.
The Messaging construct will create:
- AWS SNS topic.
- AWS SQS with a subscription to the AWS SNS topic.
- AWS Lambda function and role triggered by the AWS SQS. The Lambda function has read-only access to the AWS Aurora DB and can send events to the AWS SNS.
- AWS Lambda function triggered by Aurora streams which sends booking data to external services via AWS SNS topic.
The messaging construct will also get Aurora construct as an input parameter to define the required permissions and configuration for the AWS Lambda functions.
Rule of thumb: any shared resource used across all constructs (dead letter queue SQS or error handling mechanism) should be defined as a standalone construct and passed as input to the other constructs.
Shared Constructs
Create CDK construct libraries repositories that can be used as a project dependency across the organization. These constructs are secured and tested resources or even patterns.
You might have a cloud engineering or DevOps team creating such compliant constructs. You can read about cloud platform engineering in my dedicated blog post.
For example:
- WAF rules for AWS API Gateway/CloudFront distributions.
- SNS -> SQS trigger pattern where SNS and SQS have encryption at rest defined with required CMKs.
- AWS AppConfig dynamic configuration construct.
CI/CD Guidelines
This section describes guidelines for correct stack deployment, environment modeling, and developer experience regarding local tests and development.
Stack Deployment
“Development teams should be able use their own accounts for testing and have the ability to deploy new resources in these accounts as needed. Individual developers can treat these resources as extensions of their own development workstation” —AWS CDK guide
Several options come to mind; choose the one that makes more sense to you by considering company size, budget and AWS accounts managing overhead.
Ensure you use the guidelines and best practices for managing those accounts with AWS Organizations and AWS ControlTower.
Smaller companies use strategies such as account per developer where you can deploy the ENTIRE products line and its plethora of microservices into one account to develop locally, make changes, push them, and test against local stable versions immediately.
- Local development experience is excellent.
- Integration tests are more straightforward and can be done locally. However, mimicking actual service data per AWS account can be challenging and reduces test practicality.
- Observability across many accounts is hard to maintain.
- Managing a large number of accounts considering the small company size.
When the developers open a PR, the pipeline deploys to a different account. Account per stage is the recommended approach as it lowers blast radius in case if a breach or errors.
However, larger companies might choose a different approach.
Sometimes, deploying the entire company portfolio to a single account is impossible due to complexity, resource quotas, and required knowledge to deploy the services.
A viable option for large companies consists of the following:
- Different service teams get their separate AWS accounts — reducing friction, conflicts, and chances to reach AWS service quotas per AWS account.
- Each CI/CD pipeline stage gets its AWS account (dev, test, staging, production, etc.).
- Developers develop on the dev account together. They deploy their service CDK stacks to the same account. However, each stack has a different name/prefix to remove possible deployment conflicts.
- Developers test against actual services deployed in other accounts.
- Integration tests across multiple accounts can sometimes require cross-account trust and can be more challenging.
As you can see, each method has its pros and cons, and there’s no silver bullet.
Model Your CI/CD Pipeline Stages in Code
Use local configuration files and environment variables in conjunction with code conditions (‘if statements’) to deploy different resource configurations to various accounts and stages.
For example:
- A development account might have different policies (retain policy set to destroy, for example), but a production account will practice a resilient configuration.
- Each stage will have different secrets and API keys – reduce blast radius if one account is breached.
- The production account will define higher AWS Lambda reserved concurrency or enable provisioned concurrency to remove cold starts.
- Different billing models for AWS DynamoDB in various stages. Reduce costs in dev accounts, and maximize performance in production.
Resiliency & Security Guidelines
Define Retain Policies
In a production environment, it’s critical to define removal policies on stateful or critical resources (Databases) as ‘Retain’ so you don’t delete and rebuild the data they hold.
In the development environment, it’s OK to delete the resources once the stack is removed or the resource id changes.
This practice will reduce your cost and orphan resources in the long run.
AWS CDK Tests
Use AWS CDK tests to ensure vital resources are not deleted, and meaningful resource connections remain intact.
These tests are done in synth time so there's no way you are deploying a broken version.
See examples for infra tests in my CDK template test file.
The tests verify in synth time, prior to deployment that the API GW resource exists.
See more examples in the AWS CDK testing guide.
Security Defaults are Not Good Enough
Always strive for least privilege permissions and roles. Each AWS Lambda should have its own role with its minimum subset of permissions.
There are many security guidelines for different resources. Sometimes, they are reflected in AWS CDK default values such S3 block public access by default. However, sometimes are not.
It’s up to you to always have security in your mind:
Should this resource reside in a VPC? Should I put IAM authorization of this API gateway path? perhaps turn it into a private API Gateway?
Luckily, there are tools to help you cover your tracks. You should use tools such as CFN Nag and CDK-nag.
Checkout the CDK nag tests that I implemented in my CDK template service stack.
CDK nag checks are added to the stack and run during deployment. Any potential security breach will fail the deployment.
Secrets in CDK
Don’t store secrets in your code, whether CDK or AWS Lambda handler. Use AWS SSM encrypted strings or AWS Secrets Manager to keep them safe.
However, how do you pass the secrets to the CDK, so they are deployed to AWS Secrets Manager?
One viable option is to store the secret as a GitHub/Jenkins/CI secret and inject it as a CDK parameter or environment variable during the deployment process.
Always Think About Resiliency
Avoid changing the logical id of stateful resources.
"Avoid changing the logical id of stateful resources. Changing the logical ID of the resource results in the resource being replaced with a new one at the next deployment. The logical ID is derived from the id you specify when you instantiate the construct..” — official AWS CDK Best practices.
It’s always best to be safe than sorry. Mistakes can happen.
It takes one naive refactor to a stateful CDK resource (move around constructs, rename logical id, etc.) to delete an entire production database and customer data.
Backups
Create backups for your stateful resources; use built-in backups such as DynamoDB point-in-time recovery or use AWS Backup to create custom backups.
Changes Visibility
You can use a tool called ’CDK notifier’ to provide more visibility to your pipeline in every PR.
Now, before every PR merge, you can visually understand the changes in your infrastructure. Green are resources that are added, and red are deleted.
Aware developers can now visually understand if there’s a catastrophe looming in the PR.
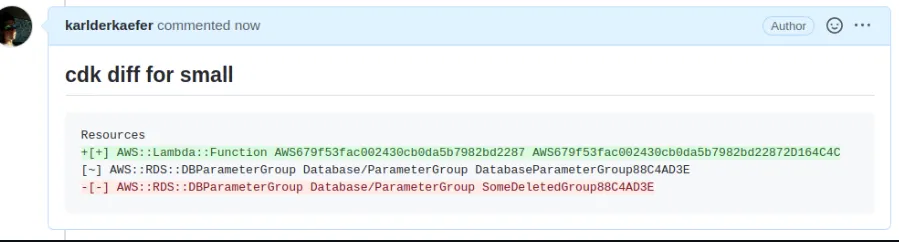
Thank you, Roy Ben Yosef, for this valuable tip!
General Development Tips
RTFM
When using CDK built-in constructs and resources, read the documentation. Make sure you understand every parameter and its definition before starting to work.
Those optional parameters usually hold security or resource policies that you should explicitly define.
Write Your Own IAM Policies
A powerful capability of CDK constructs is the plethora of built-in IAM related functions that abstract away the real IAM policies. For example: A DynamoDB table construct can grant a role read-write permissions (‘grant_read_write_data’).
While that abstracts the IAM policies that are added to the grantee role, the side effect is that.
- Developers don’t understand IAM policies and what their changes grant to the role. Yes, they can read the function documentation, but many developers don’t go the extra mile.
- Some of these functions add permissions that your role does not require, which is against the ‘least privilege’ security principle.
Notice how we explicitly set the required IAM action for DynamoDB - nothing less and nothing more.
Conclusion: define your own AWS IAM policy document. You can define inline policies or complete JSON IAM policies. When possible, try to limit the resources section to a specific resource: a particular bucket, a specific AWS DynamoDB table, etc.
While less intuitive, you will learn about IAM and create better-secured services, and the policy will become more precise and less abstract in the long run.
See this blog for more examples.
Read the AWS CDK IAM module documentation for more details.
Console First Approach
When developing CFN — try to use the console first, understand the relationships between items, then try to create the CFN objects and connect them.
Don’t Over Abstract
Writing AWS CDK is writing code. As engineers, we thrive and take pride in cool abstractions and tricks. However, as with everything else in life, please don’t overdo it, especially with infrastructure code. I’d accept minor code duplication — AWS Lambda function definition with a clear environment variables definition and configuration over a complicated factory method that creates multiple Lambda functions.
Infrastructure code is critical, so it should be readable and organized as much as possible. However, that doesn’t mean that code duplication is always accepted. Find the balance that works for you between abstraction and readability.


