

So, let’s talk about the latest cool kid on the block: the Model Context Protocol (MCP).
“But wait, isn’t everyone and their grandma already talking about this?” you might ask.
And you’ll be absolutely right.
So how is this yet another MCP article going to be different?
Well, for starters - it’s heavily inspired by Peppa Pig (didn’t see that one coming, did you?). And second - I’m going to make a bald claim: I was one of the first people on this planet to actually implement a working MCP server running a stateless Streamable HTTP natively on AWS Lambda without using custom transport or external bridging layers and…
Wait! Pause! Halt! Stop right there!
Say what?? What transport? What layer? What are you even talking about!?
Exactly. Good point.
Let's start from the beginning. And if you’re the kind of person who skips the lore to get to the boss fight right away, feel free to skip directly to the Model Context Protocolsection. But be warned - you’ll be missing all the Peppa Pig drama.
GenAI, the Days of Yore
Unless you’ve been orbiting Pluto for the last couple of years, you’ve probably heard of generative AI more than once. It’s everywhere and lately everything seems to be about it. But even those of us (myself included) rolling our eyes and claiming the “GenAI fatigue” have to admit - the tech behind it is just mind-blowing.
I use GenAI daily, at work and at home. It boosts my productivity and helps me to be a funnier dad. Because honestly, my brain just can’t invent a new bedtime story starring Elsa, Peppa, and Super Kitties every single night. (But my 5-year-old still insists).

As engineers, it’s important we understand the how, not just the hype. GenAI is a buzzy marketing term, powered by the technology called Large Language Models (LLMs) under-the-hood. Those models are really, REALLY good at generating content based on two things:
- What they’ve seen before (training)
- What you’re asking them about (prompt)
Training means feeding models mountains of data — books, Wikipedia articles, blog posts, legal docs, StackOverflow threads, Reddit rants, you name it. The best models even go beyond text, they can generate music, voices, images, and videos.
Prompting is how we interact with them. You give a prompt, the model responds — that’s called inference. For example, ask it for a poem about serverless, and voilà…

The Limits of Knowing (and Not Knowing)
Here’s a crucial thing about LLMs - they know what they know, but they don’t know what they don’t know. (Should I copyright this gem?)
What I mean is - models are fully, totally, absolutely dependent on the data they were trained on. Ask LLM “What’s 2+2?”, and you’re likely get the correct answer. But not because the model is doing math like your calculator. It has just seen enough examples during its training to predict the most likely correct response.
Quick thought experiment. Ask your favorite AI Assistant:
“Without using any external tools or searching the web, what’s the weather in my location right now?”
That’s a trick question. You’re asking for real-time info, but telling it not to cheat. A trustworthy LLM will reply: “I don’t know.” Why? Because LLMs have a knowledge cutoff date, typically 6-12 months ago. They don’t have built-in awareness of live data. No real-time events, no automatic API calls, none of that.
But there is one interesting trick. Let’s see it in action.
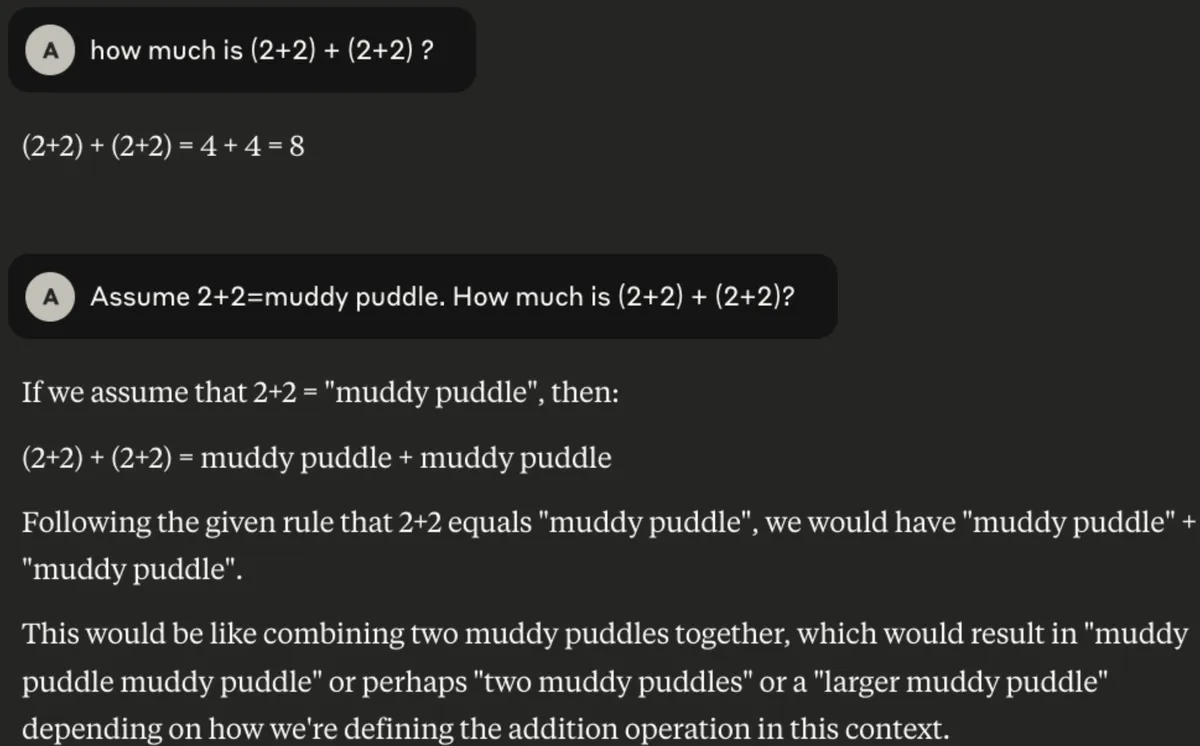
See the difference? In the second prompt, I didn’t just ask a question - I added context. And LLM happily used it to tailor a better answer.
So… does this mean the knowledge that LLM do not possess can be augmented through the prompt?! Yes! And this opens up a whole new world of possibilities!
Retrieval-Augmented Generation
In reality, typically you’re not talking to LLM directly. You’re using an AI Assistant - a tool or interface that acts as the bridge between you and the actual LLM.
- ChatGPT is an AI Assistant, built by OpenAI, that can use different LLMs like GPT-4.
- Claude Desktop is another AI Assistant built by Anthropic and it connects to LLMs like Claude Sonet or Claude Haiku.
- Generic AI Assistants like Goose or CLINE can connect to a wide variety of LLMs via APIs.
One powerful technique to enrich prompts is called Retrieval-Augmented Generation (RAG). Say you have a massive enterprise knowledge base - thousands of docs, files, database records. What if you could make that knowledge searchable and feed relevant pieces into the LLM prompt? (Curious? Google “vector embeddings”). That’s exactly what RAG does - it retrieves relevant context, injects it into the prompt, and lets the model generate a response.
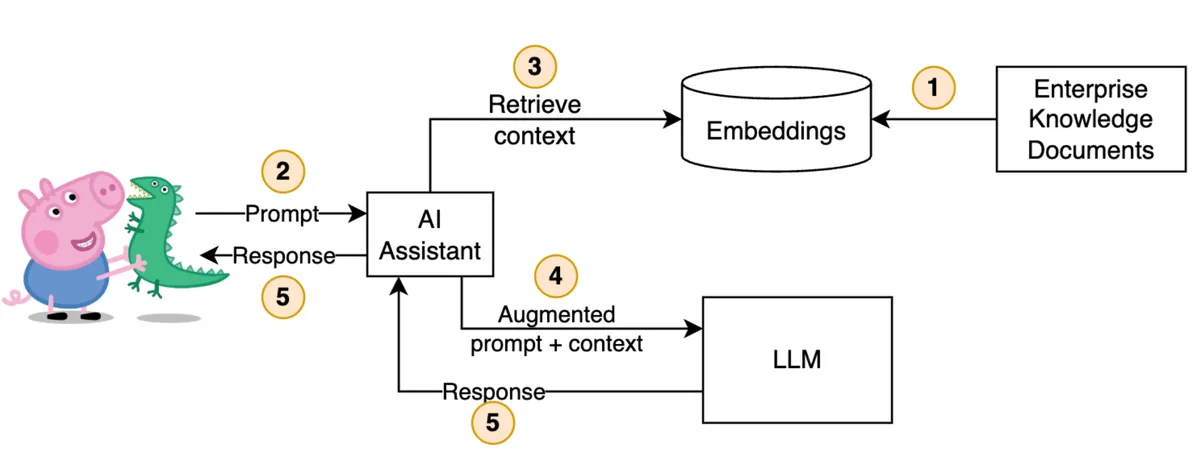
This lets LLMs answer questions they normally couldn’t, for example:
- What’s our company’s travel reimbursement policy?
- Why is the Jenkins build failing for AcmeProduct?
- Give me 3 examples of similar litigation cases we’ve successfully handle
RAG boosts inference accuracy and relevance by adding factual context from your knowledge base. But, as always, there are considerations to be aware of. It uses historical pre-processed data stored for retrieval, and it follows a pretty rigid pattern: retrieve, then generate. No dynamic decisions or real-time interaction. The level of autonomy is pretty low.
Unless… What if your AI assistant could use a wide array of external tools, for example searching the web on demand?
Let’s test a scenario that’s very real to me at this very moment, as I’m writing this article in a dark hotel room, quietly waiting for my family to wake up so we can head out for a fun day in the Peppa Pig Theme Park in Dallas TX.

(Claude Desktop, Claude Sonet 3.7)
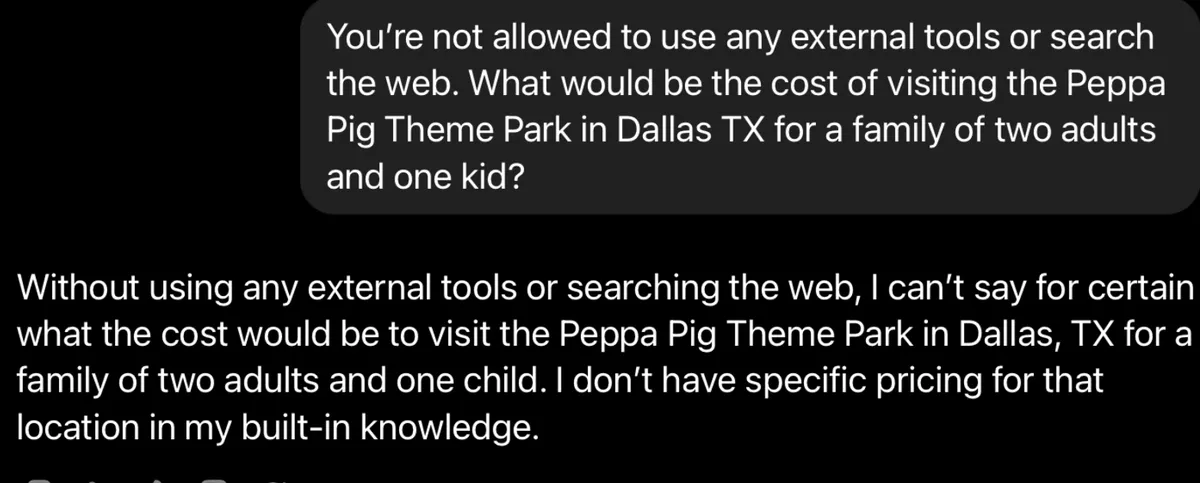
Point proven. LLMs don’t know what they don’t know, especially when you explicitly tell them not to use any external tools. Now, let’s see what happens when I lift this restriction.
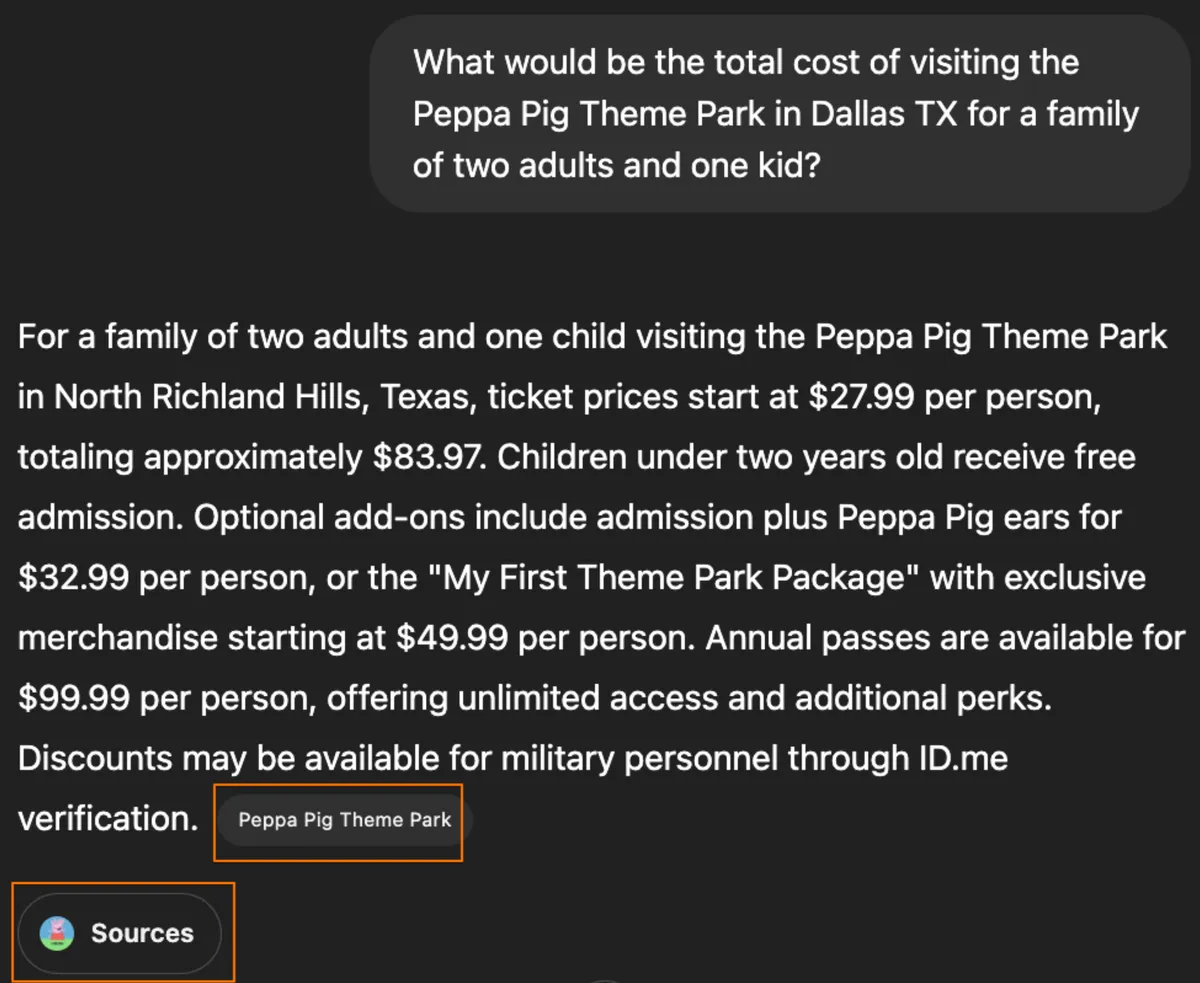
Suddenly LLM is way smarter! But how does this magic work? Behold Agentic AI!
Agentic AI Assistants can dynamically fetch context in real time on-demand. See those buttons I highlighted above? Those are auto-augmented data sources. When processing the prompt, ChatGPT found the Peppa Pig Theme Park website all by itself and pulled in the info needed to answer my question.
Agentic AI
Unlike RAG, which typically relies on static, historical data, the magic of Agentic AI lies in its ability to retrieve fresh, real-time context the moment a prompt is received. But it doesn’t stop at reading and responding - Agentic AI can also take actions! How? Well, if an LLM can generate instructions for HTTP GET, why not HTTP POST, right? Agentic AI does more than merely return you the LLM response - it can make autonomous decisions about next steps and execute them.

Imagine you ask Agentic AI Assistant for information about a specific resource in your AWS account. The assistant uses LLM to generate a relevant AWS CLI command, run it, feed the result back to LLM, and give you a clean, human-friendly answer. And that’s just scratching the surface.
Let’s get back to Peppa Pig. When I asked about ticket prices, Agentic AI searched the web, found the official site, navigated to the pricing page, parsed it, and summarized it for me.
But it could do so much more, for example it could also check the weather, buy tickets, book a hotel… basically plan the whole trip.
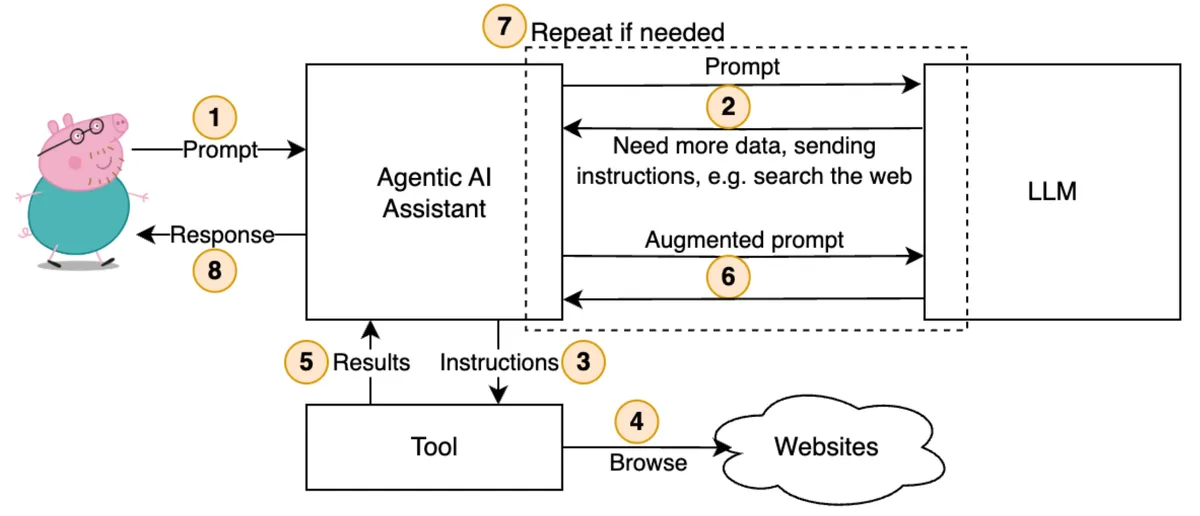
The true power of Agentic AI Assistants lies in their ability to dynamically tap into external tools, execute tasks, make decisions, and build plans — all in real time. A code assistant can scan your repo and explain what’s broken. A travel assistant can juggle flights, hotels, weather, and car rentals to build an itinerary. A financial assistant… Well, you get the idea.
But, as usual, with great power comes great… integration challenge. Vendors like Claude Desktop, Amazon Q, and ChatGPT want to integrate with as many tools as possible. Meanwhile, tool makers want their tools to be compatibe with all the top AI Assistants. But here’s the snag - every system speaks a different language (SQL, REST, gRPC, WebSockets) and even when the transport matches, the interfaces don’t.
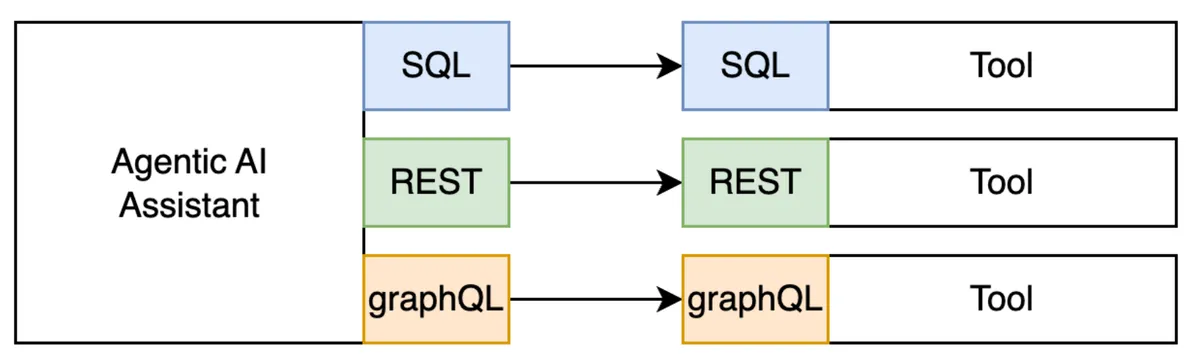
It’s the Wild Wild West of integrations and communication protocols. No standardization means AI Assistant vendors have to custom-integrate every tool, and tool vendors rely on them to do it. It’s a tangled web of mismatched protocols, dependencies, priorities, and pain.
Model Context Protocol
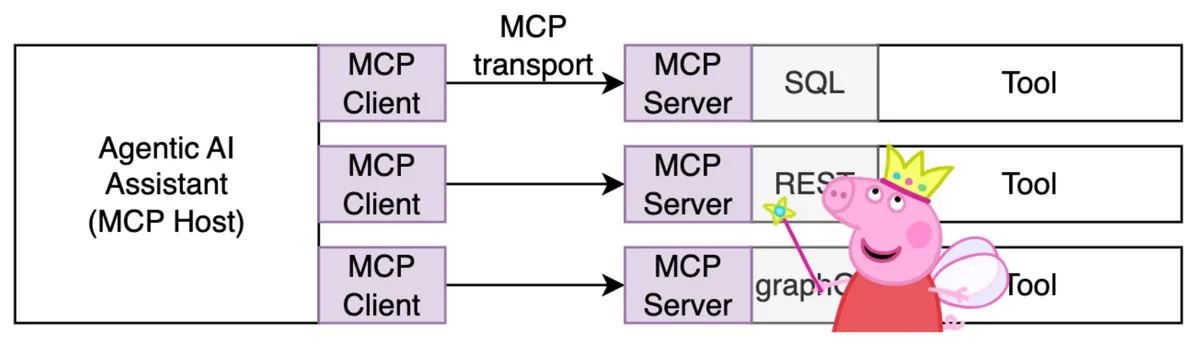
And here we are, finally talking about MCP - the Model Context Protocol. Introduced by Anthropic in late 2024, MCP was built to solve the integration problem described in the previous section. It’s the superhero we've been waiting for - a standard protocol that bridges the gap between AI Assistants and the countless tools they need to work with.
As the name suggests, MCP is all about giving models more context. But here’s the real power move - it shifts the integration responsibility to tool vendors, giving them the flexibility to make their tools AI-ready on their terms.
Before we dive into the technical stuff, a quick heads-up - MCP is still very new, basically in tech-prototype diapers. This article might age fast as the protocol evolves. That said… so far adoption has been insane. In less than 6 months, the community has spun up hundreds of MCP Servers. Just look at the AWS serverless MCP samples, the official MCP servers repository, or mcpservers.org, or Glama's MCP server directory, or mcp.so, or… you get the idea.
⚠️ Important reminder - Only use MCP Servers from trusted sources. Always.
MCP Internals
At its core, MCP defines four entities - Hosts, Clients, Servers, and Transport. This terminology might raise an eyebrow at first, especially if you’re used to the more traditional idea of clients connecting to servers running on hosts. The world of MCP is a bit different - Clients run on Hosts and connect to Servers. Both Clients and Servers are just pieces of software, and the Host is any system capable of running that software. For example Agentic AI Assistants such as Amazon Q or Claude Desktop can be hosts in the MCP ecosystem.
Transport is another key concept, it defines how Clients and Servers communicate. Not the protocol, but the channel. There are several native methods outlines by the specification:
- Standard Input/Output (stdio). With this method, the Host starts a subprocess running your server and uses stdin and stdout to communicate between the Client and Server. This means the Host, MCP Client and MCP Server must all run on the same machine. A heads-up for developers: you can’t use stdout for logging in your MCP Server (goodbye, console.log()). The client will try to interpret anything you write into stdout, which can cause unexpected output to break things.
- Streamable HTTP. This method allows the Client and Server to communicate over HTTP. It can be stateful, but also supports a fully stateless model. This will be the core option I focus on below.
There was previously an option for stateful HTTP with SSE (Server-Sent Events) connections, but it was recently deprecated in favor of the Streamable HTTP, which supports both stateful and stateless connections, making it ideal for building Serverless MCP Servers.
All right, enough theory! It's time to get our hands dirty. We’re going to build an MCP Server that simulates getting tickets to the Peppa Pig Theme Park (because obviously). We’ll use the official TypeScript SDK, which was the first to support Streamable HTTP. (Sorry, Ran! I know you love Python, but I’m a Node.js guy 🤷♂️). This MCP Server will simulate checking available time slots and ordering tickets.
As of writing this article, there are no official hosts/clients that support Streamable HTTP just yet (this is what happens when you’re working with bleeding-edge tech). So, we’ll start by testing locally with Claude Desktop over stdio. After that, we’ll deploy this MCP Server to AWS Lambda and expose it via API Gateway. And to complete the picture, we’ll also build our own MCP Client using Streamable HTTP transport to test the whole workflow end-to-end.
Step 1 - Tools and resources
MCP specification defines several server features - the capabilities that servers expose to clients.
Let’s start with Resources. These allow MCP Servers to share data that provides context to language models. While not a perfect analogy, you can think of resources as of GET requests - they’re read-only and are not supposed to result in any changes. Let’s create a "timeslots" resource, which lists all available time slots for booking tickets.
Next up are Tools, which function more like POST requests. Tools let models interact with and perform actions on external systems. In our case, we’ll create an “order-tickets” tool that accepts the selected time slot and quantity as parameters. This is how Peppa Pig fans get their tickets!
See the hard coded dates and order number in the above screenshots? We’ll use them to validate that the system is working properly end-to-end.
A crucial point: every resource or tool in your MCP Server should have a clear description. This is how LLMs understand what your tool does and when to use it. Remember, LLMs don’t know what they don’t know (I really should trademark that). If you don’t explain that your “order-tickets” tool is for booking Peppa Pig Theme Park tickets, the LLM won’t know what to do with it. Think of the description as a manual for a robot with great language skills but little context.
Step 2 - MCP Server
The next thing to create is the actual MCP Server. The screenshot is self-explanatory.
Same as above, make sure your server instructions tell LLMs when and how it should be used.
Step 3 - Testing locally with stdio
Let’s talk about transport. We’ll start with stdio transport because it’s the easiest way to test your MCP Server locally, especially if you’re using Claude Desktop or any other AI Assistant that supports the MCP spec. With this setup, your AI Assistant (aka the Host) spins up your MCP Server as a subprocess and talks to it using the good ol' standard input and output.
Now I can plug my MCP server into Claude Desktop. To do this, edit the Cloud Desktop config file - claude_desktop_config.json. This is where you tell Claude how to launch your server and connect over stdio:
Let’s restart Claude Desktop and see our amazing Peppa Pig MCP Server in action. If everything is wired up correctly, Claude should automatically launch my MCP Server using the command I supplied in the config file and communicate with it using stdio. And the timing couldn’t be better - as I’m writing this, my kid is waking up! I need those tickets STAT!
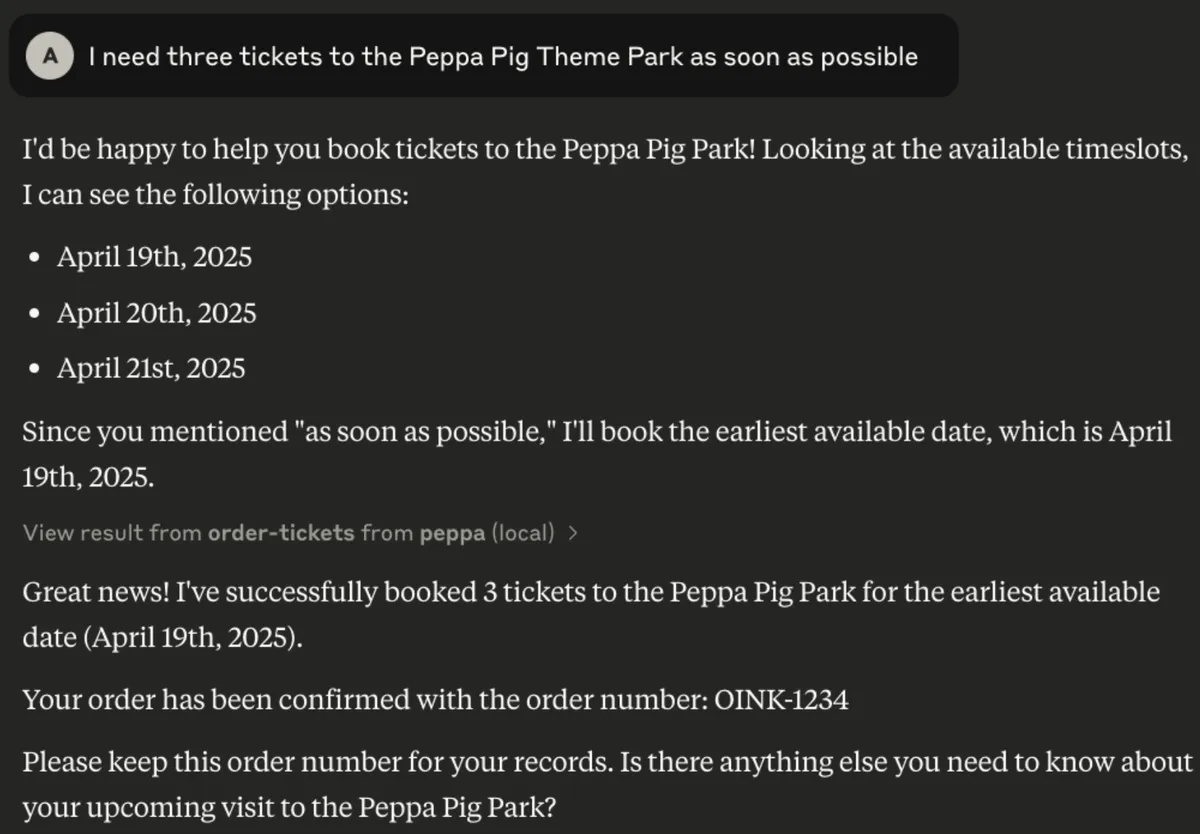
Nice! My (fake) Peppa Pig MCP Server is working! Notice the dates and order number are exactly what we have hardcoded previously.
Right now, my MCP Server is just a piece of software on my local machine. Sure, I could throw it on GitHub, but let’s face it - not every Peppa Pig fan is tech-savvy enough to clone a repo and run the code locally. Also, I’m not exactly the best programmer in the world (shocking, I know), so when bugs pop up or improvements are needed, how do I notify everyone to grab the latest source code version?
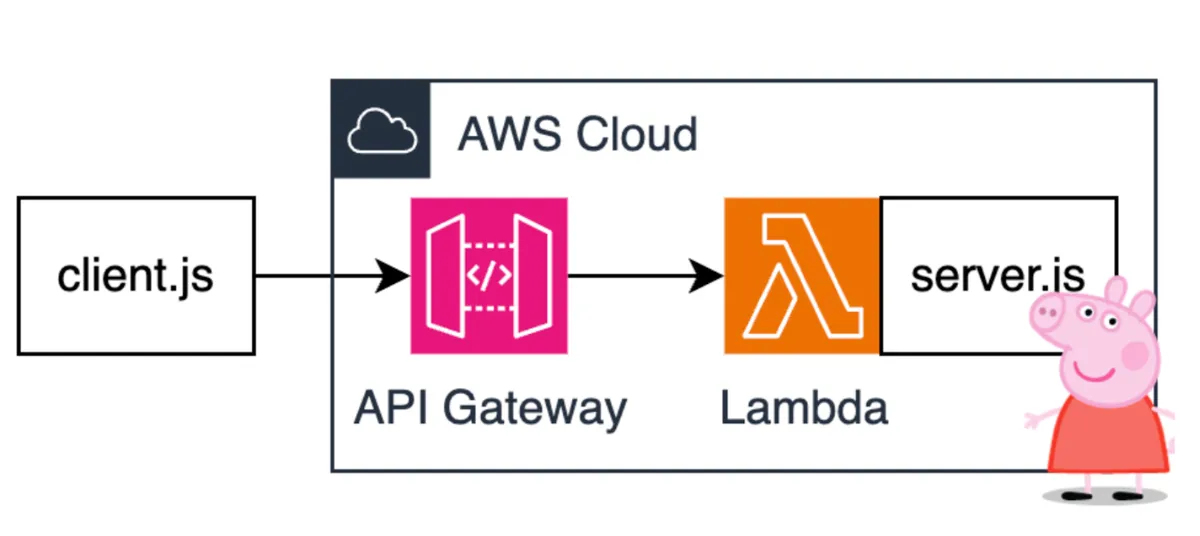
This isn’t a new problem in software development, and the solution is turning my MCP Server into SaaS. And since I want to keep things as lightweight and low-maintenance as possible (no infrastructure headaches), I’m going serverless with AWS Lambda and Amazon API Gateway. Clean, scalable, and, best of all, no servers to babysit.
Step 4 - Running on Lambda and API Gateway
In order to run my MCP Server on Lambda, I need to do a few things. First off, I need an HTTP server, and good old Express fits the bill just fine.
I’m host my MCP Server as a Lambda function, which means ephemeral compute. I don’t want to worry about synchronizing state across different execution environments (just yet). To keep my MCP Server stateless, I’m explicitly setting the sessionId generator to undefined when creating a new StreamableHTTPServerTransport instance, I’m also setting the enableJsonResponse property to true, ensuring the MCP Server returns the response immediately via standard HTTP.
My express server will listen for POST requests and process them using the transport I’ve created previously. I also want some error handling in place, in case things go south.
The last step on the backend side is making sure my Express app, which is just a plain HTTP server, knows how to play nice with requests coming from the API Gateway. You can do this with a library like serverless-express, or go full modern with the shiny Lambda Web Adapter.
Step 5 - IaC
You didn’t expect me to tell you to click a hundred buttons in the AWS Console manually, did you? Of course not. We do things the right way around here. Check the repo, use Terraform to deploy, and don’t forget to "npm install”.
Step 6 - Testing the remote MCP Server
Deploy it, run the client, see the magic.
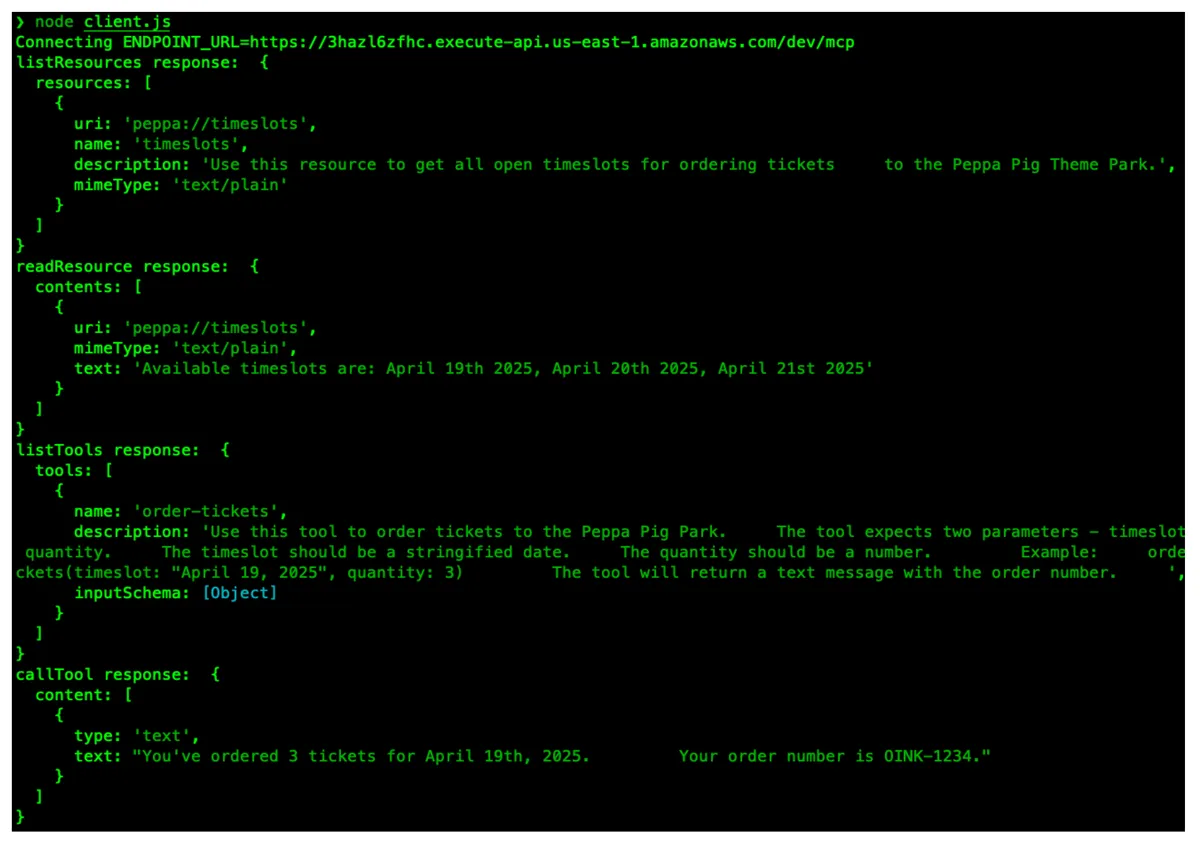
And that’s a wrap! You can grab the full source code from the Peppa MCP Server on Lambda repository, fork it, tweak it, use it as inspiration to build your own MCP Servers. Whether you’re booking Peppa Pig tickets or building the next-gen devtools for your team - welcome to the future of Agentic AI!
Check out Ran's AWS Lambda MCP Cookbook to get started with MCP and Lambda with all the best practices:
https://github.com/ran-isenberg/aws-lambda-mcp-cookbook
Conclusion
In this article, you’ve explored the power of Model Context Protocol (MCP) and Agentic AI, showing how they’re revolutionizing the way we interact with AI Assistants. From enhancing LLMs with real-time data to enabling AI to take action on our behalf, these technologies are paving the way for more intelligent and dynamic systems. And along the way, we built an MCP server running natively on AWS Lambda, all while gearing up for a family trip to the Peppa Pig Theme Park (priorities, right?).
As AI continues to evolve, innovations like MCP are making it easier to integrate real-time context and automate tasks in a smarter way. So, whether you're building your own server or simply making your next family trip a little smoother, the future of AI is bright.


