

It happened to all of us. You order a shiny new tech gadget or a pair of new jeans online.
The order takes its time and then fails due to momentary network failure. So you submit it again, and the order goes through this time; success!
However, two weeks later, you realize your credit card was charged twice by mistake.
Why did it happen?
It happened because the shop's orders API did not implement API idempotency correctly.
And that's the subject of today's post.
In this post, you will learn about serverless API idempotency, why it's essential, and how to implement it in a sample serverless "orders" service with AWS Lambda functions, AWS CDK, and AWS Lambda Powertools for Python. We will also write an end-to-end test to validate that API idempotency works as expected.
What is API Idempotency
API calls can fail as a result of network IO issues. That is why clients implement a retry mechanism. However, in some cases, a retry can cause problems, like in the duplicate order scenario I described in the intro section.
The server side might have processed the API request the first time. That request might have created numerous side effects, created resources, made credit card charges, and whatnot. However, when it is retried for the second, third, fourth, and so on with the same input, it must not create any side effects and return the same response as the first request in order to be idempotent.
Or to summarize it nicely, according to this excellent article on making retries safe from the Amazon's builder library:
An idempotent operation is one where a request can be retransmitted or retried with no additional side effects
Ok, so how can we make our Lambda functions idempotent?
The short answer is with a cache. The longer answer is described below.
Serverless Idempotency Implementation
Hash & Cache
At its essence, idempotency is achieved through cache infrastructure and service SDK that uses that cache efficiently.
We will deploy a DynamoDB table as a cache mechanism for the infrastructure part.
For the service side SDK, we will use AWS Lambda Powertools Idempotency utility
Idempotency key is a hash representation of either the entire event or a specific configured subset of the event, and invocation results are JSON serialized and stored in your persistence storage layer - powertools documentation
When your Lambda function is invoked with a new event, we calculate an idempotency key based on that event (or a subset) and store the function's response in the idempotency cache table as a new idempotency record with the hash as its key.
When the Lambda function is triggered again with the same event, its hash key resides in the idempotency table, and the JSON serialized value is returned as a response instead of running the business logic all over again.
Let's review a sample service, the 'orders' service I've used in my cookbook blog series, implement this flow in a sample serverless service and understand what the AWS Lambda Powertools idempotency utility does.
The 'Orders' Service
The 'orders' service is a serverless service template project I created on GitHub. It helps you get started in the serverless domain with all the best practices, a working CI/CD pipeline and CDK infrastructure code.
It is a simple service: Customers can place orders and purchase many items.
They can place an order by sending a JSON payload containing the customer name and the number of items they wish to purchase as an HTTP POST request to the /api/orders path.
The API GW triggers an AWS Lambda function which stores all orders in an Amazon DynamoDB table (the Orders DB) and returns a JSON response containing the unique order id, customer name, and amount of purchased items.

Now, let's make this serverless API idempotent.
Our goal is to ensure that when customers retry the same order request, they will get the same response back, and no new order is written to the Orders DB.
Orders Service Idempotency Design
Let's review a use case where a customer sends an HTTP POST request (representing a new customer order) to our service; the service creates the order and saves it to the database.
Then, the API GW's response gets lost due to network I/O issues.
Thinking the order still needs to be created, the customer sends a retry request, the same payload again.
Let's see how our solution behaves in each of the requests.
First Request
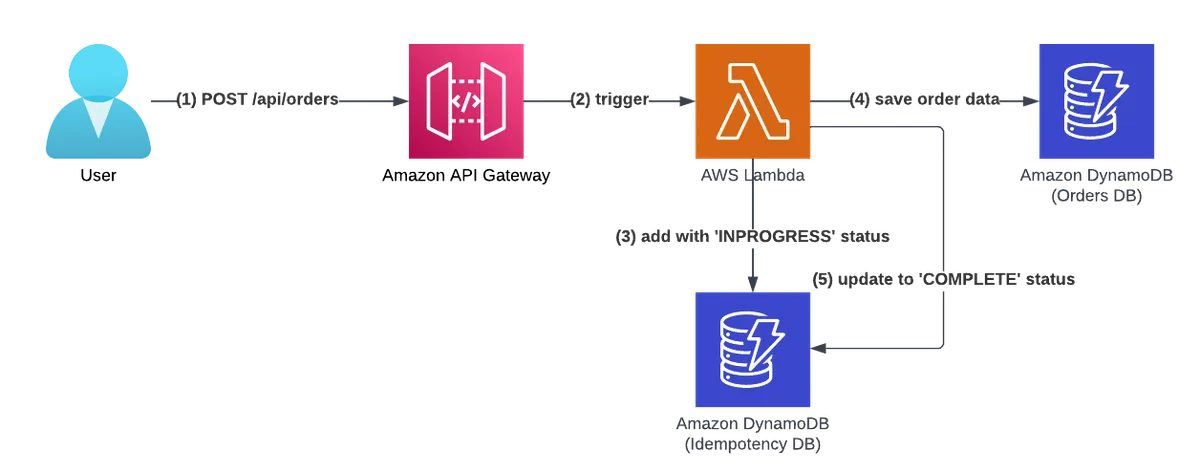
Please note that the idempotency layer's code runs before Lambda's function business logic code and runs again after it finishes.
The order of events:
- The user sends an HTTP POST request to /api/orders.
- Amazon API GW triggers our Lambda function.
- The idempotency layer hashes the request payload and adds a new record to the idempotency table with an 'IN PROGRESS' state.
- The Lambda function runs the business logic code, saves the new order to the DynamoDB and Orders DB tables, and returns a JSON object response.
- The idempotency layer takes the JSON object response from the handler, updates the idempotency record's state to 'COMPLETE,' saves the JSON object response into the idempotency DB and returns it to the customer.
What has just happened?
The Lambda function handles the order request successfully, and a new order is inserted into the Orders database. In addition, the idempotency layer added a new record to the idempotency DB. The record's key is a hash value of the input order event, and its value is the business logic code's JSON response that was sent back to the user as a response to its API call.
This record will have time to leave (TTL) set since the customer might want to create a new order with an exact payload in the future and we want to allow that.
Read the idempotency record expiration documentation about expiration time.
If you want to learn more about the idempotency record and its states, head to the AWS Lambda Powertools documentation. The record can change states or even get deleted, depending on function timeouts or unhandled errors and exceptions that might occur during the business logic code.
Retry Flow
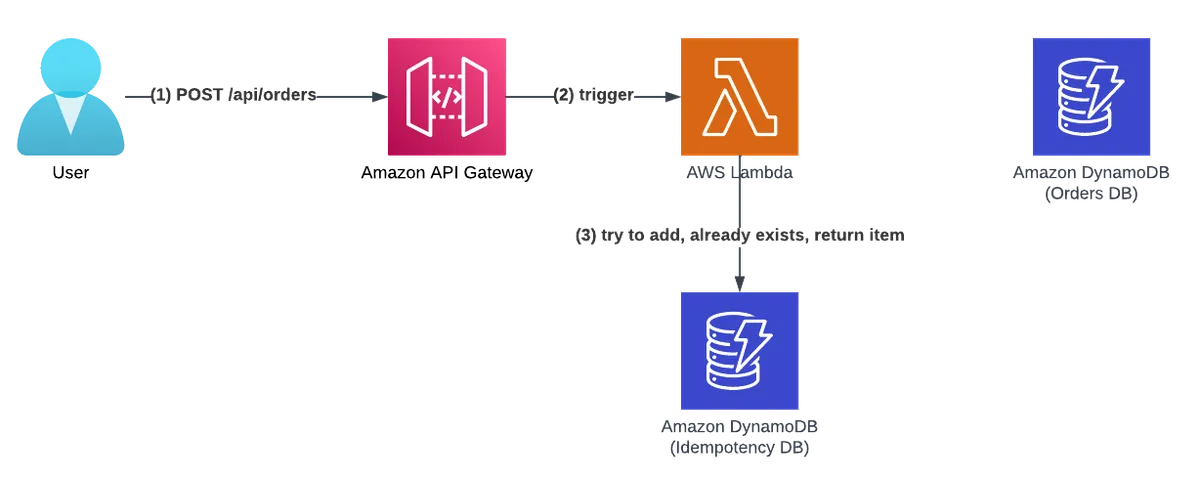
Due to momentary network issues, the response to the first API call was dropped. Our customer notices the error and sends a retry API request with the exact payload.
The order of events:
- The customer retries the API call and sends an HTTP POST request to /api/orders with the same payload as the first request.
- Amazon API GW triggers our Lambda function.
- The idempotency layer hashes the request payload, finds a matching idempotency record in the idempotency DB table with a 'COMPLETE' state, and sees that it has not expired yet.
- The idempotency layer serializes the idempotency record's JSON value and returns it as the HTTP response. The handler's business domain logic code does not run.
What has just happened?
The Lambda function did not run the business code. It returned the same response as in the first API call. In addition, it did not cause any new side effects, such as a new order getting saved in the Orders DB.
As you can see from the diagram, there was no interaction with the Orders DB in this flow.
Our API is now idempotent, as expected.
However, once the idempotency record reaches its TTL time, the idempotency layer will remove it and treat any hash-matching request as a new valid order to create.
How do we set the TTL, then? That's up to you; I'll set it to around 5 minutes.
However, if you want even more finetuning over figuring out whether a payload is matched and considering extra input headers, check the idempotency payload validation documentation.
CDK Code
Let's create the dedicated DynamoDB idempotency table that serves as our cache and provide our lambda function with the required permissions.
Lines 10-18 define the table. Notice that the primary key is set to 'id' in line 13 and that we enable the TTL feature in line 16.
In lines 19-20, we grant our lambda function role the required permissions.
The project's CDK API construct file is on GitHub (it might be different from the sample code here).
Lambda Function Code
There are two ways to add idempotency to the Lambda function code:
- Add an idempotency decorator to the handler.
- Add an idempotency decorator to an inner function.
Let's review the first implementation and then compare it to the second and decide which one is better.
We create the idempotency layer by providing the DynamoDB table name and initializing the configuration object.
In line 3, we provide the table name to the AWS Lambda Powertools idempotency DynamoDB layer. Note that in GitHub, I've switched the hardcoded table name into an environment variable.
In lines 4-7, we set the idempotency layer config and the TTL to 5 minutes.
In line 6, we tell the idempotency layer where to find the payload we want to hash and use a special capability of Powertools in conjunction with JMESpath.
In short, we tell the idempotency layer how to hash our idempotency record:
- Look at Lambda's input 'event' dictionary parameter for the 'body' key.
- For API GW events, the body parameter is always a JSON-encoded string, and you need to serialize it into a dictionary.
- Once serialized, look for two keys: 'customer_name' and 'order_item_count,' and use them for the idempotency hash.
Decorate the Handler
Now let's take a look at the handler's function code below:
All we need to do is to add the decorator in line 18 and provide it with the layer and the configuration we defined.
Let's review the pros and cons of this method.
Pros
As you can see, the usage is straightforward, which is its major strength.
Cons
When the second request triggers the function, everything is handled inside the idempotency layer in line 18. Lines 20-38 never run in that use case. Now, this is crucial to understand. If you write your authentication and authorization logic at the beginning of the handler, it will be SKIPPED in an idempotency match use case. The handler's code does not run. Running your authentication and authorization logic before the handler is triggered is okay, i.e., in a lambda authorizer or an IAM authorizer.
However, you might have a severe security issue if that's not the case. Another customer might send the same payload and get the response of the first customer since we are not taking authentication into account when calculating the idempotency hash; not great; we have just breached tenant isolation and exposed our user's sensitive information to another user or attacker!
Luckily, there's a built-in way to ensure this does not happen, and you can fine-tune the idempotency hash mechanism to consider more headers and fields so this security breach does not occur. Read the idempotency payload validation documentation.
Another area for improvement is that if you have multiple payload fields, the decorator declaration gets long and messy quickly.
Decorate an Inner Function
The second option we have is to decorate an internal function. I suggest you decorate the entry function to the logic layer, which the handler calls to handle the event once it has passed input validation, authentication, and authorization.
If you need clarification on what a logic layer is in a Lambda function, check out my blog post.
We need to alter our idempotency configuration before decorating the logic layer entry function. We no longer require to set 'event_key_jmespath' as it will be defined in the function decorator itself. The file can be found in the idempotency utility module on GitHub.
In the 'orders' service, the 'handle_create_request' function is the entry function to the logic layer. It is responsible for adding the order to the database through the data access layer.
Let's make it idempotent:
In lines 14-19, we add the idempotency decorator, set the layer and configuration parameters, and set the 'data'_keyword_argument' parameter. This parameter tells the idempotency layer how to build the idempotency record and generate the hash. In this case, we provide it with the 'CreateOrderRequest' class. This class contains the customer's name and the number of items they wish to purchase. The idempotency layer has built-in support for Pydantic classes, which is a nice touch for both input and return values. We use the 'PydanticSerializer' serializer class to tell the idempotency decorator that the expected return value of the 'handle_create_request' is a Pydantic model class, 'CreateOrderOutput', that supports serialization into a dictionary. This is a new feature that has been added in the 2.24.0 powertools version.
Pros
- Accepts Pydantic models as hash values which allow hashing multiple parameters with one class.
- Simple to use.
- It allows more flexibility as you control where the idempotency feature kicks in.
- Prevents the potential security and tenant isolation breach when placed on the logic layer entry function.
Cons
- Line 23 (register_lambda_context) is internal idempotency logic and I wish I didn't have to write it, it's not so elegant; I had to add it according to the documentation.
Now that we understand all the implementations let's see how we test them.
End to End Test
Let's write an end-to-end test that triggers our API Gateway and verifies we have an idempotent API.
In line 18, we create the create order request HTTP JSON payload.
In line 20, we send the request to the API GW HTTP address.
In lines 21-25, we assert that the request was successful and that the response schema matches our expected values, such as customer name and the number of items we sent in the request.
Now comes the idempotency check.
In line 28, we save the order id we got from the first response. This is the order id that is saved in the orders DB table. We want to ensure that when we retry the API, since the TTL has not passed, the idempotency record should reside in the idempotency table. We should get the same response as in the first request.
In line 32, we check that the order ids match. If the idempotency layer is broken, a different order id is returned.
The complete E2E test is on GitHub.
My Recommendation
So, what implementation should you choose? Handler or inner function?
Use the more straightforward handler decoration implementation if you handle your authentication and authorization before the lambda handler's code and the idempotency layer.
If that's not the case, you should always use the function decorator and decorate the entry point to the logic layer after your handler code goes through authentication and authorization and logs the request.


