

We live in an incredible era of technological advancements and innovations transforming every aspect of our lives. From artificial intelligence and machine learning to automation and big data, there is no denying that the future is here.
For example, this blog post's title was written with the help of ChatGPT to make it SEO optimized. The parrot image was made with the help of DALL-E.
What about the audio player that reads this text for you? Well, it turns out that that can be automated too.
And that's what we will discuss today, automating text-to-speech (TTS) conversion with the help of Amazon Polly.
I will provide a fully working Serverless solution on GitHub with Python code and AWS CDK. You can deploy the code and enjoy the text-to-speech transformation in minutes.
Visit the aws-text-to-speech GitHub repository to get started.
Accessibility is Important
I started my website, RanTheBuilder, to share my AWS and Serverless knowledge with the world. An accessible website promotes inclusivity and ensures all people can access and engage with content. Accessibility has taken the main stage in recent years and more websites take notice of that.
I recently noticed that Medium had added an audio player for the blog posts that read the posts for you, which is a great accessibility feature.
I had no idea how they did it, and it seemed out of reach.
However, I was inspired to take immediate action once I saw the following video on YouTube:
In the video, AWS Community builder Johannes Koch interviews Jimmy Dahlqvist, a fellow builder. They discuss how Jimmy automated his blog creation with AWS Step Functions, which resulted in the speech version of the post text with Amazon Polly.
I've never heard of Amazon Polly but felt inspired to try it myself and finally solve a prominent missing accessibility feature of my website.
I've designed a straightforward solution that heeds my needs perfectly, which are relatively modest.
Before we head over to the details, let's learn about Amazon Polly.
Amazon Polly Text to Speech Service Introduction
Amazon Polly is a cloud-based text-to-speech (TTS) service. It uses advanced deep learning technologies to convert written text into lifelike speech, allowing developers to create speech-enabled applications with natural-sounding voices.
Polly supports a wide range of languages (24 at the moment of writing), and users can choose from several male and female voices with different accents and tones (47 in total). The service also provides advanced features such as automatic speech recognition (ASR) and speech synthesis markup language (SSML), enabling developers to fine-tune the speech output's pronunciation, emphasis, and intonation.
One of Amazon Polly's strongest fortes is that it is a Serverless service. It will output audio files directly over to an S3 bucket, making it easy to incorporate into any event-driven based architecture. It will handle any text size you throw at it automatically, you don't need to spin up more machines, and you only pay for the number of characters you transform into speech.
From my short time using it, it's straightforward; text goes in, mp3 file goes out into an S3 bucket.
The free tier is impressive and will accommodate many people's needs, mine included.
Read more about pricing.
Let's see how to automate text-to-speech creation with Amazon Polly's API.
My Text to Speech Python Service
Let's go over the service's goal, design and implementation details.
The Goal
I want to be able to create .mp3 files of my blog posts and upload them to my website when working on new posts. The service must be Serverless, simple to use, and deployed with AWS CDK.
I want the usage to be as simple as possible:
- Add a new text file to the TST (text-to-speech) service 'text' folder.
- Deploy the service to AWS.
- Get an mp3 file delivered to my email address.
I can then upload the mp3 file to my website and publish the new blog post with an audio player built into the post that plays the mp3 file, thus resolving a major accessibility feature my website was missing!
To summarize: add a text file to the 'text' folder, deploy to AWS, wait a minute, and get an mp3 file delivered to your inbox. Simple!
If you want to try it for yourself, head over to the project on GitHub and follow the readme for instructions and usage.
High Level Design
From a design perspective, the service is quite simple. You've got your cloud storage entity that is used for input and intermediate processing.
Then you have two major players: producer and consumer.
The producer uploads text files to the cloud storage, which are sent to the consumer.
The consumer will transform the text file into an mp3 file and email it to an email address as an attachment.
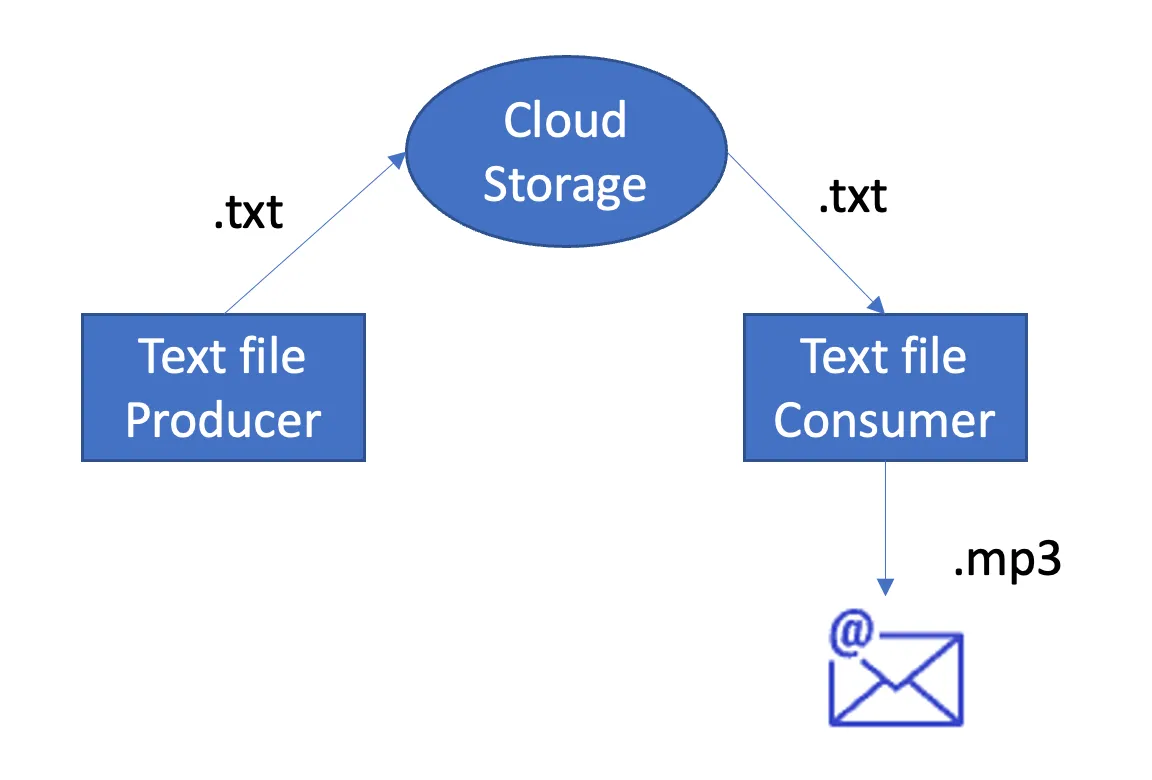
Service Architecture
Let's look into the architecture and see how I implemented each entity.
Disclaimer: This POC-level service provides automation for my needs in the simplest possible way. Code contributions are welcomed!
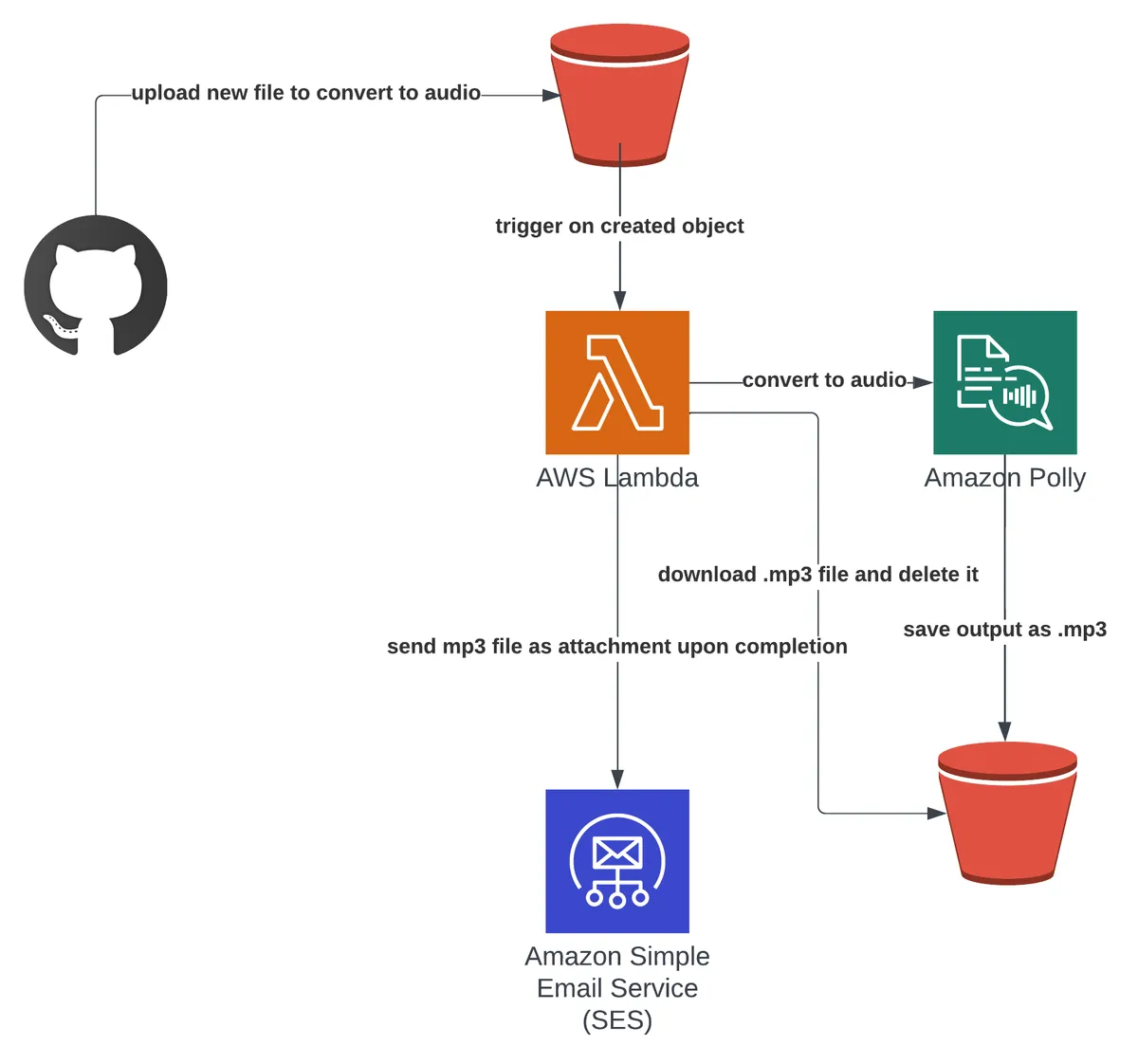
Event Flow
- The user adds a new text file to the 'text' folder on the project's root folder.
- The user deploys the service with AWS CDK (can use the command 'make deploy').
- The file is uploaded to S3.
- Consumer Lambda function is triggered with an 'object created in S3' event and reads the file name and bucket name from the event.
- Consumer Lambda function sends the text contents to Amazon Polly and sleeps/polls until the task is completed.
- Once the task is completed, the output mp3 file is downloaded from the S3 bucket and gets deleted from it. Since we email it, there's no need to store it on S3, but you can disable it and email back the object's link instead of the mp3 file.
- The Lambda function uses Amazon SES to email the mp3 file as an attachment to a predefined email address.
Service Entities Details
We use an Amazon S3 bucket for both input and Amazon Polly output storage for the cloud storage entity. Polly has native integration with Polly, so it makes perfect sense. The bucket's CDK code is in the db module.
The producer is a special AWS CDK construct that uploads files to S3 from a specific folder. I usually add one file at a time and deploy the service. You could also upload a file manually to the bucket, but that defeats the purpose; we want automation. The producer's CDK code is in the producer module.
The consumer is a Lambda function that subscribes to the S3 bucket 'on object create' events and gets triggered when new objects are written.
The function will take each event, read it and send its contents to Amazon Polly. It uses the 'start_speech_synthesis_task' API. I used Amazon Polly official sample SDK wrapper, which gets text file contents and returns the mp3 file as output - pretty simple!
The consumer CDK code is on GitHub.
And the consumer Lambda function code is on GitHub.
The Polly wrapper handler code is on GitHub.
Performance and Open Issues
For my use case, an 11,000 characters blog post takes about 40-50 seconds to turn into an mp3 file in my email address once the deployment is done. That's not bad.
You might wonder why I delete the mp3 file from S3 and send it as an email attachment.
Well, I want the mp3 file deleted and sent as an email attachment because I want to upload it to my website, where storage is already paid for, instead of storing and playing it out of my personal AWS dev account.
You might also wonder, well it's a nice implementation, but, is it optimal? Is it the best design option?
Well, no.
The consumer Lambda function waits and polls Polly until its synthesize task is finished, which is a bad practice both performance-wise and cost-wise. However, for a POC project that runs once every two weeks (when I publish a new post), that's acceptable, for now, at least.
A better solution is to use Step Functions with a wait state. Polly can notify an SNS topic when the task is completed; that SNS can send a message to an SQS message and then to a Lambda that will wake up the step function with a wait token to continue sending the file to my email.
So, why did I choose a Lambda function over a step function state machine implementation? A couple of reasons:
- The AWS Polly wrapper allowed me to advance quickly, and it does everything in the same process (it does the sleep & poll for you), so the Lambda function is simple to use over the step function, which will not be able to use the SDK.
- You can't develop and debug step functions in the IDE, unlike Lambda functions. I wanted to provide value as fast as possible for this use case and get to results quickly.
- It's more about providing accessibility and learning something new, and less about creating the best possible production-ready solution.
So, in this case, should you use the Step function state machine over a Lambda function?
Yes, of course. I will do it as part of v2 of the service, but code contributions are also welcome!
Another area of improvement is that I'm not using lexicons or synthesis markup language (SSML), which enables developers to fine-tune the speech output's pronunciation, emphasis, and intonation. This can be a game changer but requires more research to understand the feature and how to automate it.
And lastly, error handling, retries, and tests - still need to be created. I tested the code in the IDE (called the Lambda handler with a generated event) and during deployment time as an end-to-end test.
Want to learn more about how to test Serverless applications? Check out my serverless testing best practices post.


