

Getting started with AWS Lambda and serverless development is fast and straightforward. However, security hardening is often either overlooked or done later. In many companies, security becomes a top priority only when it's too late and something has already gone wrong.
In this post, we'll walk through common Lambda security pitfalls — leaky exceptions, tenant isolation breaches, and over-permissive roles to insecure secrets management — and show you how to avoid them. We'll explore topics like dependency scanning, input validation, authentication, and tenant-safe caching.
To make it even easier, I've included a Lambda Security Checklist that you can use as a quick reference to apply these best practices to your functions.
My Security Experience
As an AWS serverless hero who has worked in cybersecurity my entire career (currently at CyberArk), security is close to my heart.
Below are key AWS Lambda security practices I’ve learned over five years of building and securing production-grade serverless services.
These insights combine real-world experience with principles from the OWASP Serverless Top 10.
Lambda Security Best Practices
Disclaimer: This post focuses on practical Lambda security fundamentals every developer should follow. It's not a substitute for a complete security review or penetration test — but it will help you build more secure Lambda functions from the start.
So, with that out of the way, let's start with the first topic.
Injection Attacks Due to Poor Input Validation
Ever heard of SQL injections? These types of attacks can still happen with Lambda if you are not careful. You might put yourself at risk when you pass unsanitized incoming payload as is and run it as an Aurora query. Other risks can be unexpected crashes or behavior due to unexpected input. The solution is straightforward.
Run input validation at the beginning of the handler. Write your schemas as strictly as possible and use a whitelisting approach to reduce the risks of edge cases and missed values. Regexes and enums are your friends.
If you use Python, you have amazing open-source libraries like Pydantic and Powertools for AWS Lambda (the Parser utility) that validate and serialize your input.
I wrote an extensive blog post about input validation best practices that you can follow.
However, validation and object serialization do not stop at the handler. You should do this at any point in the function interacting with an external service.
Poor Authentication or Authorizations Mechanisms
Authentication is:
Authentication is the act of proving an assertion, such as the identity of a computer system user - Wikipedia
and authorization on the other hand is:
the function of specifying access rights/privileges to resources - Wikipedia
Let's talk about API Gateway and Lambda integration.By default, your API is public and can be abused by pretty much everybody, their bot friends, or evil AI agents.
I wrote an extensive guide explaining the differences between authorization and authentication, which you can find here.
Use a cognito authorizer, custom Lambda authorizer, or IAM authorizer (best used for service-to-service communication). Be aware that API Keys are not an authorization or secured mechanism as they do not provide proof of identity.
If you opt for a custom Lambda authorizer, JWT validation is the standard. You can use the data in the token to enforce fine-grained authorization using CEDAR policies and AWS Verified Permissions.
Dependencies and Secure Code Scanner
Use tools like Amazon Inspector and Snyk to keep your dependencies and open-source libraries up to date. These scanners also notify you as soon as a tool has a CVE or has been compromised. In addition, they scan your code for secure coding issues and suggest fixes.
Make sure to add these scans to your CI/CD pipeline as a gate before function deployment so you don't deploy code with issues to production.
Lastly, don't forget about your IaC either. Use tools like cdk-nag or cfn-nag to scan your CF template for security misconfigurations prior to deployment. These tools go beyond Lambda functions.
AWS SDK Version Mismatch
This one is less about security and more about removing potential unexpected behaviors. AWS Lambda has a few default libraries, and you cannot control their versions. However, if you add these libraries, like AWS SDK (boto for Python), to your uploaded zip file or layer, you will override the default version. This practice guarantees you use the same version as locally in the cloud - no surprises.
Add Web Application Firewall (WAF)
AWS WAF is important for Lambda security because it helps block malicious traffic — like SQL injection, XSS, or bot abuse—before it reaches your Lambda function, reducing risk and unnecessary invocation costs. It can reduce the chances of denial of service attacks.
It's beneficial to place WAF in the following use cases:
- CloudFront -> API Gateway -> Lambda function
- API Gateway -> Lambda function
- CloudFront -> Function URL Lambda
Want to learn more about WAF? Check out my blog post, "AWS WAF Essentials: Securing Your SaaS Services Against Cyber Threats."
Safe Secret Handling
Don't store secrets in your code or environment variables. Store them in the SSM Parameter store or the secrets manager. Use environment variables to store the secret name, ARN, or SSM path.
If you want to know how to choose between them, stay tuned — my next blog post will cover that!
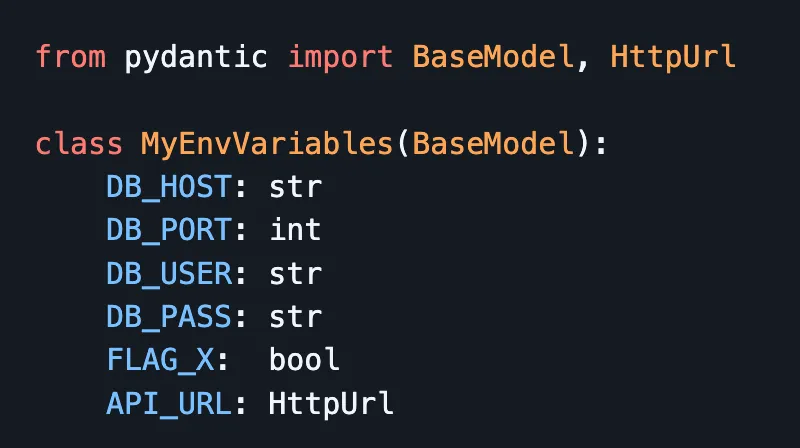
In addition, I advocate for safe environment variable parsing and serialization. This guarantees that there will be no unexpected behaviors or misconfiguration.
For Python, you can use my aws-lambda-env-modeler open source, which utilizes a schema validation approach of environment variables upon handler invocation with Pydantic.
You can read the extended best practices for environment variables in my "AWS Lambda Cookbook - Part 4 - Environment Variables Best Practices" post.
Usage in handler, both parsing and getting serialized variables:
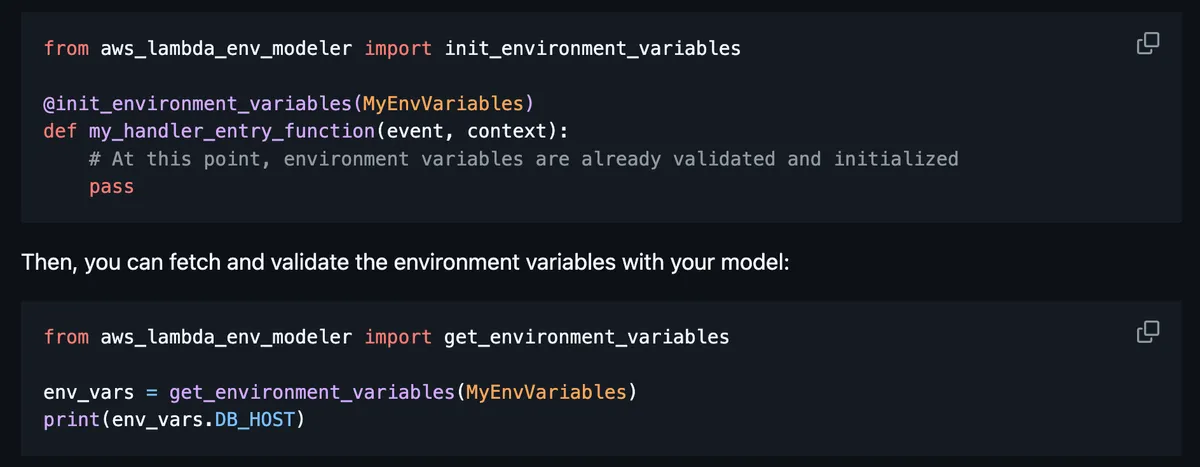
Reserved Concurrency
Placing reserved concurrency on your Lambda function can reduce the effects of denial of service attacks. However, It does not block the attack itself — it just contains it.
From the AWS documentation:
By default, your account has a concurrency limit of 1,000 concurrent executions across all functions in a Region. Your functions share this pool of 1,000 concurrency on an on-demand basis. Your functions experiences throttling (that is, they start to drop requests) if you run out of available concurrency.
Use reserved concurrency to reserve a portion of your account's concurrency for a function. This is useful if you don't want other functions taking up all the available unreserved concurrency. In case an attacker causes a concurrency spike for one function, other functions won't be affected, and the attacker will reach throttling limits. Now, while there was a de facto denial of service, it didn't cause the entire service to go down, just one function (unless they attacked them all at once).
Another way to reduce the risk of concurrency limits is to spread your services across multiple AWS accounts, each with its own quotas and limits.
Rate Limiting
Rate limiting is an advanced mechanism to prevent system abuse. Since we rely on authorization and authentication as entry gates to our services, we might encounter scenarios where a customer’s machine might be compromised and flood your service with valid but excessive requests.
To mitigate this, consider implementing per-tenant rate limits at the API Gateway or Lambda level:
- At API Gateway: Use usage plans with API keys to throttle requests per client tier or tenant.
- With AWS WAF: Set up rate-based rules to automatically block IPs or patterns that exceed request thresholds.
- In custom Lambda logic: Maintain a token bucket or other mechanisms using DynamoDB or Redis (e.g., ElastiCache) to enforce fine-grained limits per user or tenant.
- At the architecture level: Introduce buffering layers like SQS for non-real-time operations to decouple and absorb load spikes.
Least Privileged Lambda Role
This one is pretty straightforward. Your function should have a role that allows it to do only what it needs and only on the specific resources it requires — nothing more, nothing less, and don't use wildcard policies. Don't share roles between functions unless they require the same permissions. And yes, this will increase your overall role count and maintenance.
In AWS, it's a best practice to grant only the permissions required to perform a task (least-privilege permissions). To implement this in Lambda, we recommend starting with an AWS managed policy. You can use these managed policies as-is, or as a starting point for writing your own more restrictive policies.
AWS managed policies are useful for actions like CloudWatch logging.
Safe Error Handling
When implementing REST APIs with Lambda function and an error is returned, developers can make a mistake and expose internal implementation data through the error message. Attackers can use these implementation details to cause damage to you and your customers. The fix is simple. Have your Lambda handler catch all exception types, log the exception, and return a generic message and the correct error code.
Improve Observability and Safe Logging
Proactive monitoring and alerts will help mitigate issues before customers open support tickets or experience outages. For example, monitor Lambda function error rates, latency, and memory consumption.
For more details, check out my observability best practices post here and my Serverless CDK monitoring example blog post.
As for logging, use JSON structured logging and tools like AWS Lambda Powertools.
In addition, it sounds basic, but it's still a common pitfall: never log sensitive or customer information. Avoid logging the raw event object directly. Instead, log only relevant fields after input validation.
I've covered Lambda logging best practices in my post "AWS Lambda Cookbook — Part 1 — Logging Best Practices with CloudWatch Logs and Powertools for AWS".
Strong Encryption
Always use strong encryption algorithms supported by AWS services. Ensure all data is encrypted both at rest and in transit.
Avoid sending sensitive data (such as secrets or access tokens) in plain text between services — even over "trusted channels" like SNS or SQS. Instead, encryption should be used with AWS KMS, ideally with tenant-specific keys, to protect sensitive payloads end-to-end.
While AWS KMS doesn't yet natively support post-quantum cryptography (PQC), it's worth monitoring. AWS is actively exploring PQC as part of its roadmap (see announcement).
Encryption alone won't prevent compromise, but it significantly reduces the blast radius and helps you respond better if a breach occurs.
Tenant Isolation
In this section, I assume a pooled tenancy model, where a single Lambda function serves multiple tenants — one per invocation and a unique tenant ID identifies each tenant. However, this model introduces specific tenant isolation challenges, where a misstep could expose one customer's data to another.
The challenges are:
- Global Caches: After a cold start, subsequent invocations may reuse the same warm container. Any global variables or in-memory caches will persist. Always include the tenant ID in the cache key. Failing to do so risks data leakage across tenants. Please repeat after me: always(!) isolate cache entries per tenant.
- Session or Logger Context: Clear them at the end of each invocation if you use global or request-scoped context objects (e.g., a logger with tenant metadata or a session tracker). This is especially important in error scenarios — ensure they are reset even when exceptions are raised to avoid cross-tenant contamination.
- IAM Based Isolation: Use dynamically generated IAM policies to enforce strict access boundaries. Instead of giving the Lambda role broad permissions, have it assume a role that uses inline policies to allow access only to the current tenant's data. This approach, as described in AWS's blog on dynamic IAM policy generation, leverages IAM to enforce isolation and reduce the risk of developer mistakes.
Update Lambda Runtime Versions
Always use the latest Lambda runtimes — don’t wait until the last minute to upgrade. Once a runtime reaches end-of-life, it no longer receives security patches, putting your function at risk. AWS sends you alerts and call-to-action emails, but you should stay proactive: schedule and plan upgrades in advance. See AWS documentation for more details.
Lambda Code Signing
Code signing for AWS Lambda is an advanced security feature that ensures only trusted code is deployed to your functions. It's useful if you need strict control over code integrity — especially in regulated environments.
However, it comes with limitations:
- It's not trivial to automate. AWS does not provide easy ways around it.
- You cannot sign extensions and third-party layers unless you create a copy of them.
- Signing profiles don't support automatic rotation, so manual management is required.
Summary
In this post, I shared real-world best practices for writing secure Lambda functions, from input validation and safe secret handling to tenant isolation, encryption, and IAM best practices.
We also touched on proactive monitoring, safe logging, rate limiting, and more advanced topics like Lambda code signing and runtime upgrades.
These practices align with the OWASP Serverless Top 10 and are designed to be practical, actionable, and production-proven.
Check out my AWS Lambda Handler Cookbook template for hands-on examples and more detailed implementations.
To help you implement these patterns in your own projects, I created a Lambda Security Checklist you can use as a quick reference during development and code reviews.


