

High-quality API documentation enhances customer satisfaction. In my previous post, I presented means to generate OpenAPI documentation for serverless APIs with Powertools for AWS. Building on that foundation, this piece delves into automating and seamlessly integrating this process into our CI/CD workflow.
In this post, you will learn how to generate OpenAPI documentation for your serverless APIs automatically, keep it in sync with your code, and safeguard against API-breaking changes.
Serverless OpenAPI Documentation Recap
In the previous post, I presented a method to generate OpenAPI documentation for Python Lambda function-based APIs, utilizing Powertools for AWS Lambda and Pydantic.
I generated an OpenAPI documentation for a serverless API consisting of an API Gateway and a Lambda function. I defined the HTTP input payload schema and ALL the possible HTTP responses: their codes and complete JSON payload with Pydantic. Powertool's event handler utility handled the documentation generation.
It served the documentation under a new API endpoint: '/swagger.'
I used my AWS Lambda cookbook template project and added support for OpenAPI documentation. We will automate this process and add additional CI/CD automations to the project's CI/CD GitHub action-based pipeline.
Triggering the '/swagger' endpoint resulted in the following the documentation:
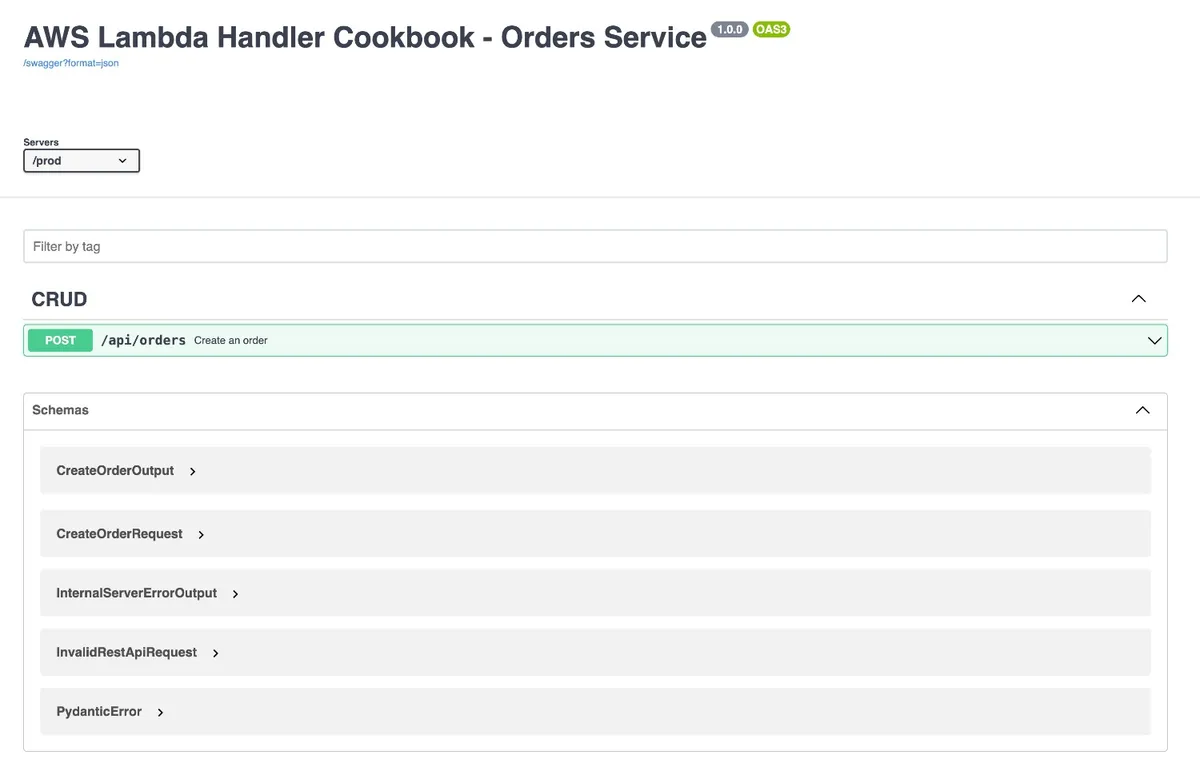
In case you didn't know, the Cookbook is a template project that allows you to get started with serverless with three clicks, and it has all the best practices and utilities that a production-grade serverless service requires.
OpenAPI Documentation Generation
Let's assume we send our OpenAPI documentation to customers or publish it on our company's website. The solution presented in the recap section, where customers access the API's '/swagger' endpoint doesn't meet this requirements. Let's find an alternative.
A possible solution is to add an automation that extracts the OpenAPI documentation from the '/swagger' endpoint and stores it in the service's GitHub repository. Once committed to the repository, we can send it to our customers or publish it on our company's website.
An entire world of automation opens up, too.
I will present the automated OpenAPI documentation generation method and two automated guardrails you must add to your CI/CD pipelines. These include:
- Keeping the local documentation file in sync with the code at all times.
- Failing a pull request in the CI/CD pipeline if it includes API-breaking changes.
It's important to note that these concepts and automations can be reproduced in any CI/CD framework, not just GitHub Actions, as presented here.
Let's start with extracting the OpenAPI documentation and storing it in the service repository in an automated and repeatable manner.
Automate OpenAPI Documentation
When a developer updates the API code, the OpenAPI documentation needs to be updated, too, so the developers should run the OpenAPI documentation generation as part of their PR. Let's automate this process.
We will use Powertools' swagger endpoint feature to generate an OpenAPI documentation in JSON format. It's already supported; we only need to deploy our service and access the endpoint.
We will write a Python script to generate the OpenApi documentation JSON file.
If you recall, Powertool's event handler exposes a '/swagger' endpoint on our API gateway that loads up a nice swagger UI. However, if we send an HTTP GET request to '/swagger?format=json', we will get our documentation in JSON format!
All we need to do is have the script download that JSON file by calling that endpoint with the query parameter and save it to an output folder.
Let's go over the script's general flow:
- Find the API gateway's URL. I used a technique where I stored the URL at the stack outputs under the 'SwaggerURL' key. I generate the stack name using a predefined convention and fetch its output. The stack output key name is a script argument, and you can use whatever key you want. I show the stack output creation in my previous post. Another option is to pass the URL as an argument to the script.
- Download the JSON file. Send an HTTP GET request to the URL with a '/swagger?format=json' query parameter.
- Store the downloaded file at the output destination; the default is '/docs/swagger.'
- Now that you have the file commit it as part of your pull request.
The script is fully documented and can be found in the generate_openapi.py source file.
You can also run the command 'make openapi' to generate the file and save it to the 'doc/swagger' folder. I added this makefile command because makefiles allow us to use a simpler command locally in the IDE's terminal and the CI/CD pipeline without exposing the internal implementation (the Python script), which we can replace and update at any time; it's just a better user experience.
In the Cookbook project, I prefer to save the JSON documentation under the 'docs/swagger' folder so it can uploaded to my project's GitHub pages website. GitHub pages are a great way to let customers view your APIs, at least for open-source projects.
Now that we have the documentation in our GitHub repository, we can commit it and generate an updated version every time we make changes to the API.
Let's take it even further with two crucial automations.
GitHub Actions & CI/CD Automation
This section will introduce two CI/CD automation critical to the OpenAPI documentation process. I assume you can generate the documentation, either in the process I presented or some other way.
Both automations are already part of the AWS Lambda cookbook template CI/CD pipeline.
Code is in Sync with Documentation
The first automation is a crucial one. We want to ensure that our committed documentation file represents the true state of the API and is indeed in sync with the code. If we send the documentation file to customers or publish it online, we must ensure it's always current.
We can't always expect customers to use the '/swagger' endpoint; and in some cases, we might not want to expose it.
Currently, while we can generate the documentation and commit the file, the developers need to remember to update the documentation and run the script presented in the automation part above. If they forget, our committed file is out of sync. API customers will not appreciate misaligned documentation and the frustration that comes with it when API calls do not work as expected.
We can add a new step to our CI/CD pipeline where, as part of a pull request, we validate that the committed documentation is in sync with the current API status. We will first deploy our application, and after the service deployment step, we can run this validation check. If you remember, we generate the documentation by downloading it from the '/swagger' endpoint, so we must deploy our service first.
Let's go over a GitHub action that solves this issue for us.
It's a simple step that runs a makefile command.
And here's the makefile command's implementation in bash:
In line 6, we use the script I presented at the beginning of the post to generate a documentation file out of the deployed service in the pull request. We save it as '.openapi_latest.json'.
In line 7, we compare the committed file (under './docs/swagger/) to the file we have just generated. If the developer updated the API and forgot to update the documentation (by running the makefile command 'make openapi' I presented in the previous section) in lines 10-13, we will fail the pull request.
As you can see from line 11, the developers can also run 'make pr' before they push their code. The command automatically runs and fixes all linters, formatters, and OpenAPI generation.
The complete makefile is found in the project Makefile.
As you can see, it is super simple but effective. We make sure the documentation is always in sync with the API that the code exposes.
Prevent API Breaking Changes
The second automation prevents breaking changes to your API. Sometimes, developers make mistakes and commit breaking changes without realizing the impact on their customers.
A breaking change is a change that may require you to make changes to your application in order to avoid disruption to your integration - LinkedIn API Documentation
API breaking changes come in many forms (as defined by LinkedIn API Documentation):
- Changes to existing permission definitions
- Removal of an allowed parameter, request field, or response field
- Addition of a required parameter or request field without default values
- Changes to the intended functionality of an endpoint. For example, if a DELETE request was previously used to archive the resource but now hard deletes the resource.
- Introduction of a new validation
When dealing with API changes, we must always strive to make them in a nonbreaking manner, and there are plenty of ways to do that, but I leave that for a different post.
However, I don't want to leave anything to chance and hope that the code reviewer will understand the code changes in the PR (pull request) are breaking changes.
I want the PR to fail automatically if there's a breaking change.
Now that we have API documentation as part of the PR, and we validated it and made sure it is in sync with the service code, checking for breaking changes becomes much more accessible.
After deployment, we will add a new step to our PR's CI/CD pipeline.
We will use an open-source GitHub action, oasdiff-action, based on the tool 'oasdiff.'
The tool accepts two OpenAPI JSON files, base and "new" (revision), and checks for differences. If it finds differences, it checks whether these differences (changes) between the APIs are breaking changes. In case they are, the pipeline fails. It's as simple as that.
Let's take a look at the definition:
We compare the openapi.json file under the './docs/swagger' folder that contains our documentation changes with the currently merged file at the main branch of the GitHub repository.
Let's put the utility to the test.
Let's say we add a new default parameter to our input schema 'CreateOrderRequest': 'new_order_item_count.'
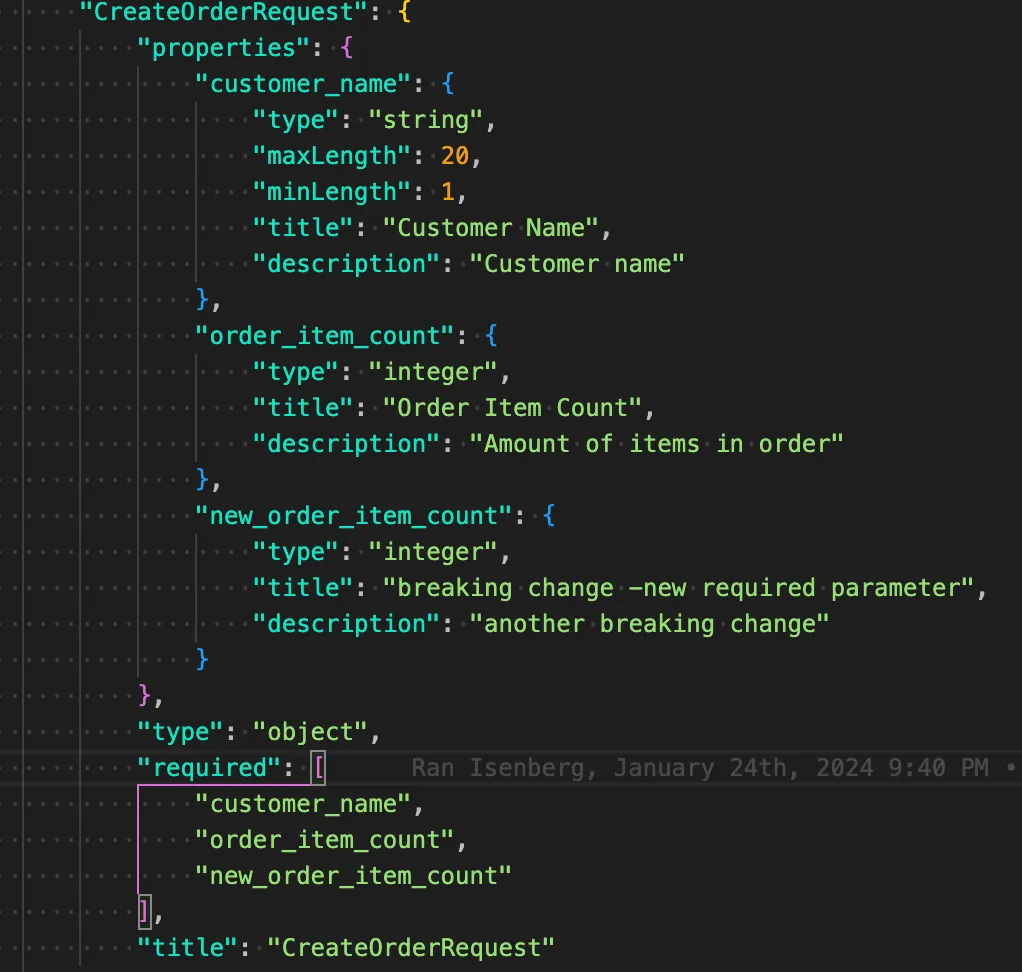
This is a classic breaking change. A better way is to either set a default value for 'new_order_item_count' or introduce an API v2 where this field is mandatory.
The developer will generate the new documentation, and the GitHub action will check for breaking changes against the current merged code.
Now, when this PR runs, we will get a failure with the following information:

The error is correct; we added a new required request property, which failed as expected; our documentation and users are saved from a breaking change!
Thank you, Afik Grinstein, for introducing this utility to me.
Summary
This concludes the second post in my OpenAPI and serverless API documentation series.
We created a script that generates OpenAPI documentation from our Lambda handlers' code and exports it; we validated that it is synced with the code and ensured it does not bring any API-breaking changes.


