

Cold starts increase the latency of Lambda functions. To address this issue, AWS offers Provisioned Concurrency, which minimizes cold start latency but comes with additional costs.
In this post, we'll explore dynamic provisioned concurrency. This solution optimizes both cost and performance, demonstrated through a detailed example and AWS CDK Python code.
Lambda Cold Start Issues
AWS Lambda cold start refers to the delay experienced when a Lambda function is invoked for the first time or after a period of inactivity. This delay occurs because AWS needs to provision the necessary resources and infrastructure to execute the function, resulting in latency before processing requests begin. One potential solution for mitigating cold starts in AWS Lambda is provisioned concurrency.
To learn more about cold starts and Lambda optimizations, check out my post on AWS Lambda cold starts in 2024.
Provisioned Concurrency
Provisioned Concurrency is a Lambda feature that prepares concurrent execution environments in advance of invocations -AWS docs
Provisioned concurrency ensures that multiple Lambda functions remain ‘warm’, meaning they are initialized and prepared to respond promptly, unlike on-demand Lambda, which initializes resources upon invocation. Pre-initializing an environment includes tasks such as code download, environment setup, and running initialization code. A common approach to utilizing provisioned concurrency is by configuring a fixed number of such environments. Learn more: AWS docs.
While provisioned concurrency offers a reliable solution for minimizing latency in AWS Lambda functions, it can have a negative side effect of increased costs, as observed by our platform engineering group at CyberArk.
In the early stages of developing our serverless SaaS services, we encountered significant latency across multiple Lambda functions. Implementing provisioned concurrency promptly resolved this issue. However, we soon encountered a notable increase in our AWS account charges. Upon investigation, we found that during periods of low Lambda workload, less than 20% of the provisioned concurrency instances were utilized, resulting in payment for unused resources.
Using a fixed number of provisioned concurrency instances is suboptimal in at least two scenarios:
- Traffic variations between AWS Accounts: Some AWS accounts serve purposes such as testing and simulating production environments, while others are used as production environments. These accounts differ in their traffic volumes, which additionally vary throughout the day.
- Regional traffic variations: Deploying the Lambda function across multiple regions means dealing with varying traffic volumes. Some regions might have higher traffic than others.
In scenarios such as the above, a fixed number of instances is typically suboptimal. A fixed high number of instances results in idle instances and unnecessary charges during low traffic, while a fixed low number of instances leads to an increase in the number of cold starts during traffic peaks. A dynamically varying number of instances could potentially perform better, optimizing both costs and latency.
Dynamic Provisioned Concurrency to the Rescue
The solution we're presenting here is designed to bring about significant cost savings and enhance resource utilization. It achieves this through dynamic provisioned concurrency management using Application Auto Scaling Target Tracking. This approach, which adjusts the number of provisioned concurrency instances in response to changes in customer traffic, ensures efficient resource utilization and substantial cost savings during low-traffic periods. Importantly, it does all this while maintaining optimized latency performance for Lambda functions.
The solution consists of the following key components:
- Application Auto Scaling Target Tracking: This component offers Lambda provisioned concurrency instance scaling without additional costs. It uses CloudWatch alarms and scaling policies. Learn more: AWS docs.
- Target Tracking policy: This is a scaling policy designed to automatically adjust the number of resources within a scalable resource group to maintain a specified target value for a specific metric. According to this policy, the number of provisioned concurrency instances is scaled to maintain theinstance level aligned with the target value. To define scaling policies for a Lambda function, Application Auto Scaling requires registering it as a scalable target. The metric can be predefined or customized. Learn more: AWS docs.
- CloudWatch Alarms: Two CloudWatch alarms are created during application auto-scaling deployment, one triggered to scale up instances and the other to scale them down according to the target tracking policy.
Application auto-scaling dynamically manages provisioned concurrency instances within a specified range by monitoring two critical alarms. These alarms are triggered in response to changes in a metric's value, ensuring that the instance count remains aligned with the configured target value. We'll utilize a customized provisioned concurrency utilization metric for this purpose.
The first CloudWatch alarm triggers when the provisioned concurrency utilization metric surpasses the target value for a sustained period of more than 3data points, lasting a minimum of 3 minutes. In response, the application auto-scaling increases the count of provisioned concurrency instances.
On the other hand, the second CloudWatch alarm triggers when the provisioned concurrency utilization metric remains below 90% of the target value for an extended duration of 15data points, lasting a minimum of 15 minutes. In response, the application auto-scaling decreases the count of provisioned concurrency instances.
As a side note, by default, Application Auto Scaling alarms are using the average statistic of the metric. According toAWS docs, the provisioned concurrency utilization metric should be viewed using the MAX statistic. Moreover, it is essential to define a custom metric targeting the maximum statistic to ensure efficient management of burst traffic loads.
The Mechanism at Work
Consider a Lambda function configured with provisioned concurrency and a target tracking policy, where the minimum number of instances is set to 1, the maximum number of instances is set to 5, and the target value for the custom provisioned concurrency utilization metric is set to 0.7 standing for 70% utilization – according to the following AWS example.
Scaling Up
The following figures show the results of our experimentation with dynamic provisioned concurrency. By examining the provisioned concurrency utilization metric in the following figure, we observe that after a sudden burst at 17:52, the provisioned concurrency utilization value has reached 1, indicating 100% utilization of the allocated instances. This value exceeds the target value of 0.7, surpassing the threshold of the first CloudWatch alarm:
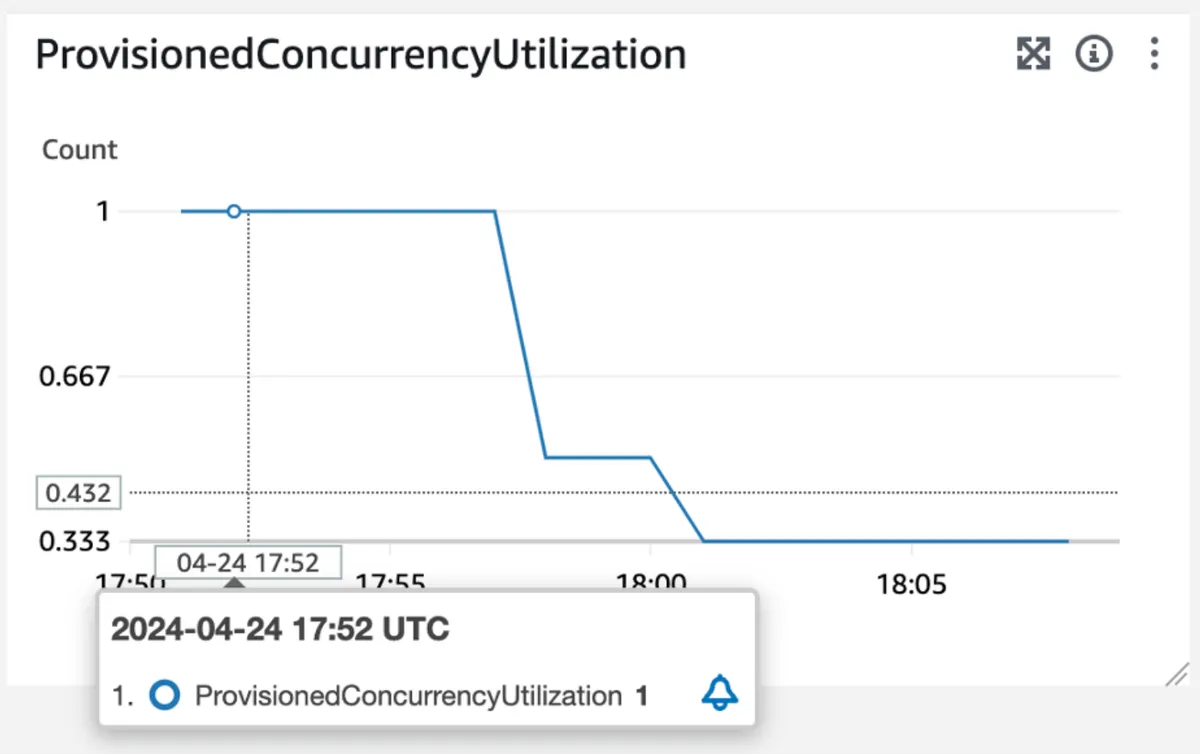
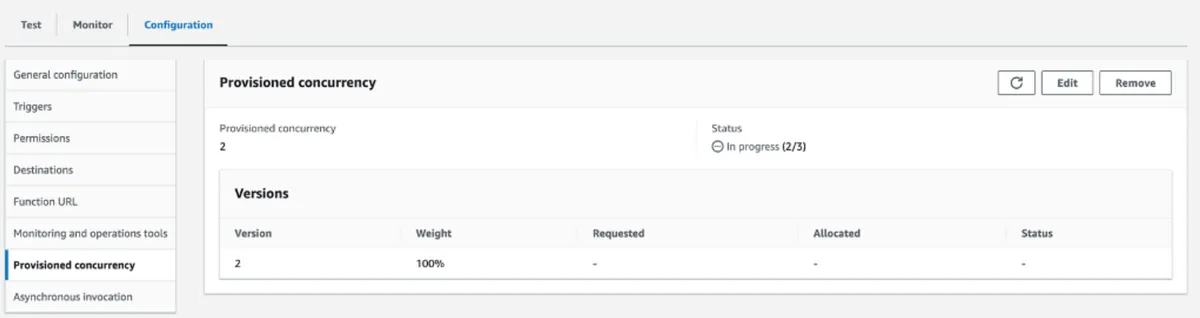
Once 3 data points are measured for this metric, the scale-up CloudWatch alarm is activated, and the target tracking scaling policy initiates an increase in provisioned concurrency instances. This action can be monitored on the configuration page of the alias, whose screenshots appear next. In this scenario, before the burst, there were two instances:
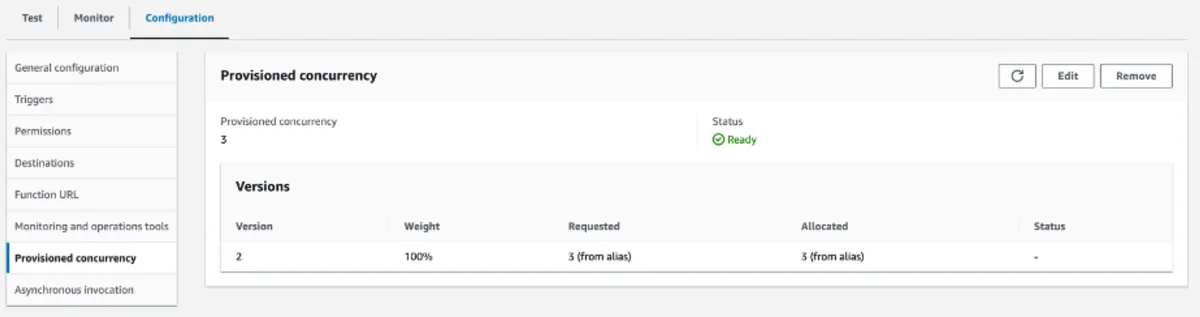
Once the operation is complete, the number of instances is increased to three.
Scaling Down
Around 18:07, the traffic decreases and the provisioned concurrency utilization also decreases to 0.3 indicating a 30% utilization of the instances, which is below 90% of the target value of 0.7, thus crossing the threshold of the second CloudWatch alarm:
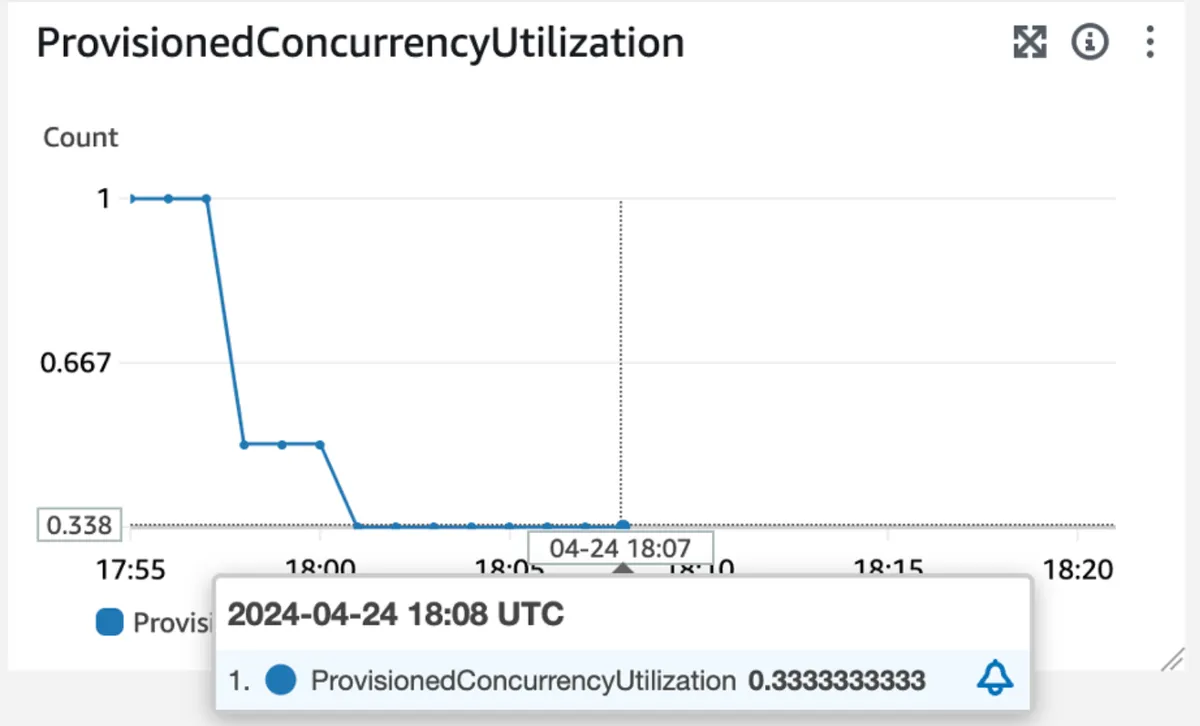
After consistent 15 data points below the utilization rate (15 minutes in our case), the target tracking policy triggers the scaling down operation, reducing the number of instances to 1.
Solution Deep Dive
Now that we have covered the key elements, and seen a simple example of how they work in practice, let's go over the implementation steps with CDK code example:
ThisCDKconstruct applies dynamic provisioned concurrency over a Lambda function according to these steps:
Create an alias:
Line 12: Creation of an alias for the Lambda, which is required for configuring provisioned concurrency. In this example, we set the initial number of instances to be 5.
Up to this line, we have defined a Lambda with provisioned concurrency configuration using a static number of instances.
Create a custom metric:
Lines 16-21: Create a custom metric based on the provisioned concurrency utilization metric.
The 'metric_name' parameter represents the custom metric's name.
The 'statistic' parameter specifies the aggregation function applied to metric data.
The 'unit' parameter indicates the measurement unit for the metric's statistic.
The 'period' parameter specifies the time interval for collecting metric data to be aggregated based on a specified statistic. In this case, the interval is configured as 1 minute, aligning with the alarm set by Application Auto Scaling Target Tracking, which has an evaluation period of 1 minute.
Now, we will configure the dynamic provisioned concurrency:
Scalable Target Registration:
Lines 23-27: Register the Lambda function's alias as a scalable target, defining minimum and maximum values for the number of provisioned concurrency instances.
Line 28: The scalable target object creation is defined as dependent on Lambda’s alias object.
Define Target Tracking Policy:
Line 29: Set up a target tracking policy based on theprovisioned concurrency utilization metric which is customized with a target value of 0.7. However, fine-tuning this value according to Lambda traffic patterns is recommended.
Solution Caveats
Setting the metric’s target value
From personal experience, setting the target value significantly higher than the minimum can result in cold starts during sudden bursts of activity. Lambda may not scale up quickly enough to handle the increased load, leading to under-provisioning. Given that scaling up takes a minimum of 3 minutes, maintaining a certain level of warm instances ready to process requests is preferable. Lowering the threshold can help prevent under-provisioning by allowing Lambda to scale up more aggressively in response to increased demand.
On the other hand, setting the target value too low within the range can lead to over-provisioning of instances, which is undesirable due to increased costs. Additionally, a low threshold can trigger frequent scaling events in response to minor fluctuations in demand, potentially increasing latency.
Ultimately, it's all about finding the right balance between cost and performance and determining how much you are willing to invest in providing the best customer experience.
Scale-down alarm
The CloudWatch alarms generated by the Application Auto Scaling Target Tracking are configured to interpret missing data as ‘missing’. To learn more about how CloudWatch alarms handle missing data refer to the AWS docs.
Regarding the scale-down alarm, if there is no traffic, there won't be any data for the metric, and consequently, the alarm won't activate. This scenario could potentially result in over-provisioning and unnecessary costs during periods of no traffic. Therefore, it's advisable to set the initial provisioned concurrency value based on the traffic pattern of the Lambda function. For instance, Lambdas experiencing low traffic can be initialized with a smaller number of instances.
Summary
We saw how we can proactively react to increases in traffic by adjusting provisioned concurrency, expecting sustained or consistent demand. Then, as traffic decreases, the service dynamically scales down provisioned instances, aligning resource allocation with the reduced workload.
By implementing a dynamic provisioned concurrency solution, Lambda functions can maintain optimized provisioned concurrency utilization, thereby ensuring efficient resource allocation and cost savings, however, it's important to note that this isn't a magical solution, perform your research and find the ideal balance that suits your specific needs.
Special Thanks
I would like to thank Ran Isenberg for dedicating his time to review this post and sharing his valuable insights and feedback,
Daniel Urieli for useful discussions and valuable feedback, and Alon Sadovski for providing valuable information.


