

Chaos engineering is a proactive methodology that intentionally introduces controlled disruptions and failures into a system to uncover weaknesses, enhance resilience, and ensure robust performance in the face of unforeseen outages.
Everything fails, all the time — DR. Werner Vogels, CTO Amazon
This is the mantra we developers need to repeat every time we plan a distributed system, and this is precisely why chaos engineering is so important.
In this blog post, you will learn about chaos engineering and how it complements the traditional SDLC (Software Development Lifecycle). We will cover the challenges of implementing chaos engineering in serverless architecture and review a few approaches with their pros and cons.
The Challenge with Serverless
Serverless architectures have revolutionized how applications are developed and deployed, offering scalability, cost-effectiveness, and streamlined management. However, ensuring their resilience can become even more challenging, although AWS manages them.
Let’s look at the following architecture:
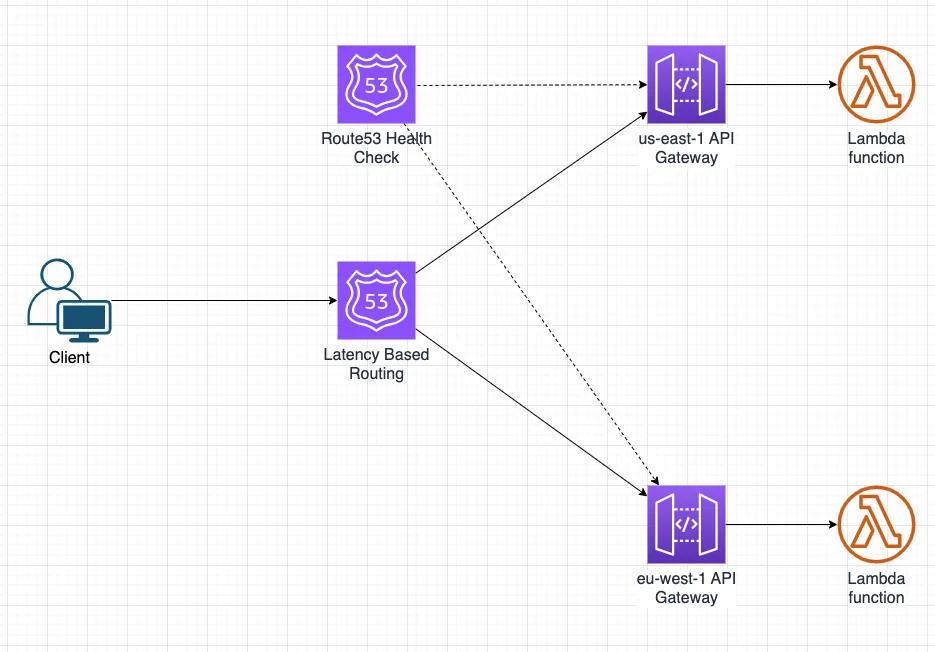
Our sample architecture is a classic serverless architecture that runs on top of AWS. It is constructed from the following components:
- API hosted in Amazon API gateway. Our API is deployed into two regions: us-east-1 & eu-west-1.
- Lambda function - triggered by our API gateway (explained in the Lambda API Gateway integration docs).
- Custom domain registered in Amazon Route 53.
- Route53’s Latency-based routing to make sure our clients use the lowest-latency API available.
- Route53’s health check to check the health of our APIs.
Given our architecture, how can we be sure our US clients can access our system in case of a US regional failure? This is not theoretical. It happened on June 13th, 2023 (you can read more in the AWS June 2023 incident summary).
Like all developers, we run integration & E2E tests (you can read more about serverless testing best practices), but is it enough? The short answer is no. Tests usually focus on verifying the functionality and behavior of the system; however, we want to verify the resilience of our system. We want to ensure our architecture is resilient to a regional failure, and even if the US region is down, our EU API will keep working and serve all customers.
This is why chaos engineering is essential. By following its principles, we can conduct experiments that simulate a region failure and verify our API is working as expected and serves requests from another region.
Conducting those experiments and introducing disruptions is relatively easy when you control the infrastructure. You can “unplug” a machine to simulate a failure. However, we use AWS-managed services, meaning we don’t control (or even have access to) the infrastructure. So, how can we simulate a region failure?
Let’s wait with this question and start by explaining what a chaos engineering experiment looks like.
Chaos Experiment
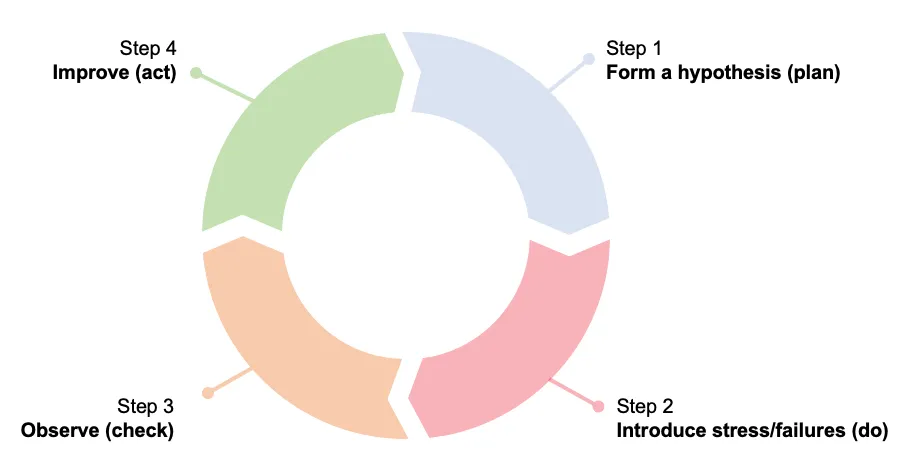
A chaos experiment is usually constructed from the following steps:
- Form a hypothesis (plan),
- Introduce stress/failures (do),
- Observe (check),
- Improve (act).
1 - Form a Hypothesis
Let’s use our example architecture and start by forming a hypothesis:
Given: we have a multi-region API gateway behind latency-based routing.
Hypothesis: failure in one region does not affect other regions.
2 - Introduce Failures
As discussed above, introducing stress and failures in our example serverless architecture may be challenging. We use AWS-managed services, meaning we don’t control (or even have access to) the infrastructure. So, how can we move forward and introduce failures?
The only component we control is our Lambda function code. Our Lambda function has two primary responsibilities:
- Health check
- API implementation
What if we changed our health function in the US region to return 404 (or any other failure response)? Let’s see what will happen:
- Route53 health check calls our Lambda and gets an error response.
- After X consecutive tries (configured number), Route53 will mark the US endpoint as unhealthy.
- Upon a resolve request, Route53 will look for the closest healthy endpoint and will always use the EU URL.
Mission accomplished. We now simulated a US region failure in our architecture.
We will stop here with our example and discuss how we can change our Lambda function to return an error code. Future posts will provide a complete example and discuss all the steps.
Injecting Failures to Lambda Function
As of writing these lines, there are two main approaches for simulating failures in a Lambda function:
- Use a library in your Lambda code.
- Use a Lambda extension (also presented in the AWS resilient serverless applications blog post).
Let’s go into more detail and explain each approach.
Use a Library in Your Lambda Code
You can use a library like chaos_lambda or failure-lambda in your Lambda code. Adding those libraries lets you wrap your handler and inject failures into it when needed. Both libraries are configurable and support the following:
- Enabled — True/False.
- Failure type — HTTP error code, exception, and more.
- Failure value — return value that matches the type. For example, 404 in case of HTTP failure type.
- Rate — controls the rate of failure. 1 means failure is injected into all requests, while 0.5 means it is injected into half of the invocations.
You can read more on the supported configuration values using the links above.
Let’s go back to our example and see how we can simulate failure in the US region:
- Add one of the libraries to our Lambda function in the US region.
- Enable it and configure HTTP failure type with a 404 value.
- Route53 calls our function, invoking the library.
- The library immediately returns 404, skipping the handler.
Use a Lambda Extension
This approach is similar to the first approach. The main difference is that we attach it to our Lambda function as a layer without changing its code.
We can use chaos-lambda-extension as our extension. For injecting failures, we should:
- Add the extension as a layer.
- Configure our Lambda to use the extension by setting the AWS_LAMBDA_EXEC_WRAPPER environment variable (explained in the extension’s README file).
- Enable a response fault with a 404 status code by setting additional environment variables (explained in the extension’s README file).
And that’s it. Now, we can simulate a 404 failure like in the first approach.
Let’s now compare both approaches.
Approaches Comparison
| Approach | Pros | Cons |
|---|---|---|
| Use a library in your Lambda code | - Straightforward to use – update your Lambda code and re-deploy | - Requires changing your Lambda code - Supports limited development languages - Problematic in case you have many functions or want to avoid deploying it to production |
| Use a Lambda Extension | - Does not require changing your Lambda code - Can support many development languages | - Requires deploying an extra component – Lambda layer - You might hit Lambda limits such as Lambda function size |
As you can see in the table above, the first approach is more straightforward. However, it might only fit applications that use a few different Lambda functions. I prefer the second approach and will focus on it in a future post.
Summary
As serverless architectures become increasingly common, there is an increasing need to verify the resilience of our systems. Chaos engineering emerges as a vital ally, offering a proactive approach to validate our assumptions against potential failures. By embracing chaos engineering, organizations can confidently navigate the complexities of serverless environments, ensuring uninterrupted services even in the face of adversity.
In this post, we focused on the challenges we face when wanting to conduct chaos experiments on a serverless architecture. Join me in my next post, in which I will go over all the steps presented in this post and provide you with code examples.


