

Amazon Simple Queue Service (SQS) is a powerful service designed to manage the messaging needs of robust, decoupled microservices.
It strongly integrates with AWS Lambda, its native partner, as a target destination.
SQS can trigger a Lambda function as its target and send the batch items as input.
However, on the Lambda function side, handling this input can get tricky, especially when errors and retries come into mind.
This is the third article in a three part series about SQS best practices
In this article, you will learn about dead letter queue best practices and how to handle failures in a correct and automated self-healing manner by redriving items back to the origin queue.
You can find all AWS CDK Python code examples in the sqs_redrive module.
You can find all Lambda Python code examples in the service directory.
Other articles in the series:
- The first article will teach you how to efficiently handle Amazon SQS batches with AWS Lambda Powertools for Python and AWS CDK code examples.
- The second article will teach you to handle Amazon SQS batch processing failures and master automatic retries with AWS Lambda Powertools for Python and AWS CDK code examples.
SQS Re:cap
In the first article, in my SQS best practices, we defined the SQS to Lambda function pattern. We implemented the AWS CDK infrastructure code and the Lambda function handler code.
In the second article, we added the notion of retries into the Lambda function and used the ability to mark partial failures back to the SQS.
However, we didn't handle use cases where ultimately, all retry attempts failed.
Note that this article builds on the code examples from the previous articles.
SQS Dead Letter Queues Best Practices
Let's review the SQS batch processing and retries best practices we defined over the previous articles in the diagram below:
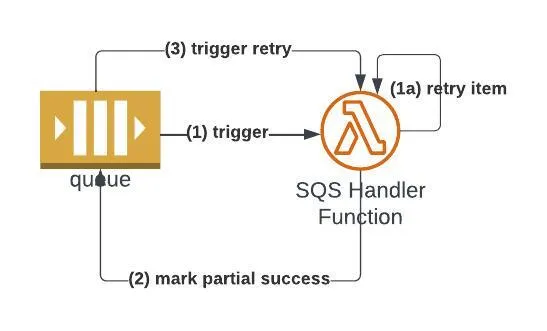
(1) SQS triggers a Lambda function with batch items. The Lambda function iterates over the batch items and handles each item and retries its processing (1a in the diagram, if required) with 'tenacity'.
(2) The function marks to the SQS what items failed processing (after multiple retry attempts) or ends with an exception if the entire batch has failed. If all items are successfully processed, the function marks that zero items failed to process.
(3) If the Lambda marked items as failed to process, the SQS will invoke the function again with a batch containing only the failed items once the SQS's visibility timeout has passed.
Handling Failures
Sometimes, you try and retry, but it just does not work. Sometimes an external service you depend on is down, or you might have a bug in your own code. No matter the cause, your Lambda could not complete processing an item, and it eventually the processing fails after a predefined number of retry attempts.
What do we do?
We want to implement another concept: a dead letters queue (DLQ).
We will send all eventually failed processing items to another SQS called a dead letter queue. Let's review the updated diagram with a new step, step number four.
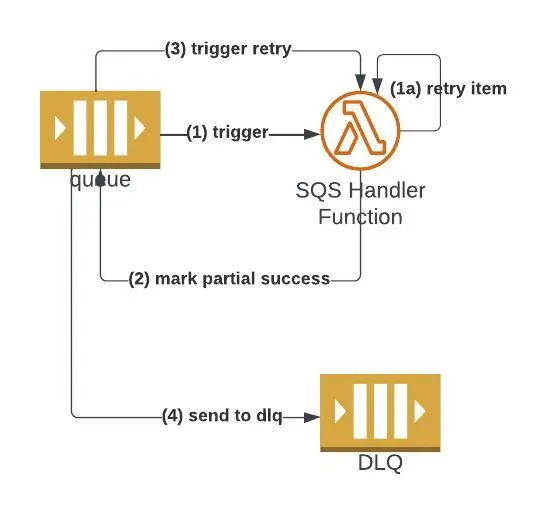
(4) SQS will automatically send eventually failed items to another SQS, the DLQ.
Now that all failed items are placed in one queue and don't interfere with the regular SQS incoming batch items, we can advance to the next stage: the DLQ redrive and self healing mechanism.
Dead Letters Queue Redrive
The DLQ contains failed batch items; great! Now we need to decide what to do with them.
If you recall, our Lambda function holds the business logic to handle batch items.
Ideally, you'd want to keep your business logic in that one Lambda instead of copying it to another Lambda that the DLQ will trigger with the failed batch items.
Luckily, on June 6th, 2023, AWS released a new redrive API that solves this dilemma.
programmatically move messages from the DLQ to their original queue, or to a custom queue destination, to attempt to process them again. - AWS Docs
The design I suggest is to create a self healing mechanism. We will use an EventBridge scheduler task that triggers a Lambda function that runs once a day (or as many times as you see fit). The Lambda function takes the failed batch items from the DLQ and redrives them, i.e., sends them back to the original SQS, where they will be sent to the batch processing Lambda function and retried all over again.
You can use this design in any service that uses the SQS --> Lambda pattern.
If you wish to learn more about EventBridge scheduler tasks, read my EventBridge scheduled tasks blog post.
Here's the redrive design diagram:

Since the redrive happens occasionally, it might be safe to assume that the batch processing might succeed in later attempts.
However, in case of continued failures, you must be able to monitor the failures and either fix them or add code in the SQS Lambda function that ignored them so they are not marked as failed again. You can learn more about observability in my Lambda observability blog post.
Now that we understand the design let's write the CDK and redrive Lambda function code.
CDK Code
Let's write the infrastructure code that defines our SQS, Lambda destination, and the dead letter queue. SQS will send failed retried batch items to the DLQ automatically once retry attempts have ended in vain.
We will expand the CDK code from the first article and add the DLQ and the scheduled task for the redrive capability.
In Lines 12-18, we define the DLQ. We enable SQS-managed encryption so we'd have encryption at rest (security first!).
In lines 24-27, we connect the DLQ to the SQS and set the maximum receive count.
The maximum receive count defined as:
The maximum number of times that a message can be received by consumers. When this value is exceeded for a message the message will be automatically sent to the Dead Letter Queue.
You can read more about it in the Amazon SQS Dead Letter Queue announcement.
In lines 35-36, we set a new environment variable for the redrive Lambda function. It needs the DLQ and SQS ARNs to call the redrive API.
In lines 41-74, we define an EventBridge scheduler task that triggers a Lambda function every day at 11 PM Israel time between Sunday to Thursday. The function's code follows below. The Lambda will call AWS SDK (boto3) to retrieve messages from the DLQ to the origin SQS. We give the task the required permissions to trigger the function.
You can find all CDK code examples in the sqs_redrive module.
Redrive Lambda Function
You can find the CDK code for the redrive function in the service stack under the '_create_dlq_lambda' function.
Please note that you should define the role permissions in a least privilege manner as suggested in the SQS developer guide and not as presented in the example.
Now, let's take a look at the function handler's code:
In line 12, we use the aws_lambda_env_modeler library (which I maintain) to parse the function's environment variables to get the SQS and DLQ ARNs. If you want to learn why validating environment variables is vital, check my post.
In lines 19-27, we call the drive API the 'start_message_move_task' API and log any exceptions.
That's it. Pretty straightforward. Once the redrive task is finished, the failed items will appear in the SQS and be sent to the SQS batch processing Lambda function to get processed again and hopefully succeed this time.
Closing Thoughts
Batch processing with SQS and Lambda is one of any serverless application's most basic use cases. However, It's easy to get it wrong.
Throughout three articles, we have:
- Defined best practices to batch process the items in a simple manner
- Implemented retry at the Lambda's level per item with 'tenacity.'
- Implemented retry at the SQS level
- Implemented a DLQ
- Implemented a self-healing redrive capability with the EventBridge scheduler.


