

Amazon Simple Queue Service (SQS) is a powerful service designed to manage the messaging needs of robust, decoupled microservices.
It strongly integrates with AWS Lambda, its native partner, as a target destination. SQS can trigger a Lambda function as its target and send the batch items as input.
However, on the Lambda function side, handling this input can get tricky, especially when errors and retries come into mind.
This is the second article in a three part series about SQS best practices
This article will teach you how to handle Amazon SQS batch processing failures and master automatic retries with AWS Lambda Powertools for Python and AWS CDK code examples.
Other articles in the series:
- The first article will teach you how to efficiently handle Amazon SQS batches with AWS Lambda Powertools for Python and AWS CDK code examples.
- In the third part of the series, you will learn about dead letter queue best practices and how to handle failures correctly.
All CDK code examples are in the sqs_redrive module.
All Lambda code is in the service directory.
SQS Re:cap
In the first article, in my SQS best practices, we defined the SQS to Lambda function pattern. We implemented the AWS CDK infrastructure and Lambda function handler codes.
However, we didn't focus on processing failures. That's about to change.
Note that this article builds on the code examples from the first article.
SQS Retries Best Practices
Let's review SQS retries best practices and the batch processing flow.
SQS triggers our Lambda function with an SQS event containing batch items.
The Lambda function will iterate each item, process it and continue to the next item.
However, what happens if one item fails processing due to momentarily network issues, external services bugs, or other random issues, and how do we recover?
So, let's review possible methods to handle failures while remaining resilient and self-healing.
There are three options to handle failures:
- Run a retry during the Lambda function's runtime, i.e., use the tenacity library (or any other retry library) to decorate any inner logic function with automatic retry. However, since with SQS, we deal with batches of records, and not just one, we need to be aware of the total runtime of the function and leave enough time for the rest of the batch and its potential retries, which can be a bit tricky, resulting in a potential function timeout.
- Use SQS's built-in support for retry. An automatic retry can be triggered in two use cases:
- A function raises an exception at the end of its execution, thus returning the entire batch to the queue.
- A function marks the partially failed messages.
- A hybrid approach - use options 1 and 2 together, which we will implement as the preferred method in this post.
Let's put these methods into a diagram:
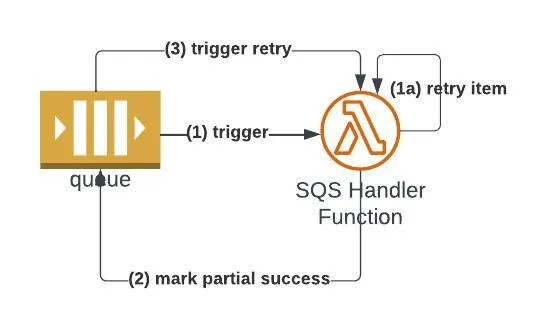
(1) SQS triggers a function with a batch. The Lambda function iterates over the batch and handles each batch item and retries its processing (1a in the diagram, if required) with 'tenacity'.
(2) The function marks to the SQS what items failed processing (after failed retry attempts) or ends with an exception if the entire batch has failed. If all items are successfully processed, the function marks that zero items failed to process.
(3) If the Lambda marked items as failed to process, the SQS will invoke the function again with a batch containing only the failed items once the SQS's visibility timeout has passed.
Keep in mind that once new items are added to the SQS, the failed batch items will be part of the latest batch that the function receives but keep in mind that messages have retention time so that they won’t remain forever on the queue.
Sometimes You Should Not Retry
Be aware that errors such as invalid input validation or verification (security-wise) should not be retried, as they will fail again and again.
However, momentarily network issues, bugs, and service downtime are dynamic in nature, and a retry strategy might be able resolve the processing issue.
Now that we understand the theory let's write the improved Lambda function code with the hybrid approach.
Lambda Handler
We will use AWS Lambda Powertools' batch utility in combination with tenacity for retries and safe handling. We will process each item in the batch, and in case an exception is raised, we will retry its processing automatically again. However, if those retry attempts also fail, we will use the batch utility's feature of marking the specific batch item as a partial failure so it is returned to the SQS.
SQS will retry that specific item again and invoke the Lambda function again. In many cases, these multiple retry attempts might be enough; however, in the upcoming part two of this post, we will look into handling the retry failures with dead letter queues.
Let's take a look at the handler we defined in the first article.
In line 12, we initialize the batch processor and put the Pydantic schema class we defined and that it's an SQS batch. The batch processor supports other batch types, such as Kinesis data streams and DynamoDB streams.
In lines 18-23, we send the event to the Powertools' batch utility start function. We provide it with the processor, the event, and our batch item handler. The item handler is our inner logic function that will handle each item in the batch.
Notice that I've mentioned that it should be a function in the logic layer, and in case you want to learn more about structuring your Lambda into layers (handler, logic, and data access), be sure to read my post about it.
All Lambda code is in the service directory.
record_handler Implementation
Let's take a look at the implementation of the item processing inner logic function.
In the first article, it looked like this:
Now, we want to add 'tenacity' to retry failed items during the Lambda runtime.
In line 9, we define the use cases to trigger an automatic retry. In this case, I defined at most two retries and to wait 2^x \* 1 second between each retry, starting with 4 seconds, then up to 10 seconds. This is a long time to retry, but it's an example. 'Tenacity' provides many retry conditions, including ignoring specific types of exceptions and other advanced use cases. Read the tenacity documentation.
In lines 10-11, we define the core item processing logic. This function must be safe for retry, i.e., it is idempotent. If it's not the case, you must make sure it is. If you want to learn about idempotency and how to make your Lambda's code idempotent, check out my API idempotency blog post.
In line 15, we log the order item we receive.
In line 17, we call the inner logic function that will process the function and automatically retry itself (thanks to 'tenacity') in case exceptions are raised.
In lines 18-20, we catch a RetryError that 'tenacity' raises when all retry attempts have failed. We catch the exception to log in and add any metadata for debugging measures. We then re-raise it to mark the Powertools batch utility that this is a failed item.
Partial Failure Mechanics
The batch utility iterates on the batch items and calls the 'record_handler' to handle each item. A failure in this function correlates to an uncaught exception being raised. The Powertools batch utility will catch it and mark the item as failed. If the 'record_handler' does not raise an exception, the item is considered to be successfully processed.
There are three potential return values for the Lambda handler according to the Powertools documentation:
- All records were successfully processed. We will return an empty list of item failures {'batchItemFailures': []}. All items are successfully processed, no items return to the SQS.
- Partial success with some exceptions. We will return a list of all item IDs/sequence numbers that failed processing. Only the failed items return to the SQS.
- All records failed to be processed. We will raise a BatchProcessingError exception with a list of all exceptions raised when processing and all items are returned to the SQS.
Closing Thoughts
Batch processing is one of any serverless application's most basic use cases.
It's easy to get it wrong. There are many caveats; for example, you add 'tenacity' but forget to extend the overall timeout time of the function, potentially reaching a timeout.
You can limit the batch size, calculate the potential time per item, assuming all items will fail after the maximum retry attempt, and set the timeout time accordingly.
In addition, you need to consider use cases where the extra retries do not work. In that case, you need to use a dead letters queue. The next blog post will tackle failures and dead letter queues best practices.


