

Software testing increases application quality and reliability. It allows developers to find and fix software bugs, mitigate security issues, and simulate real user use cases.
It is an essential part of any application development.
Serverless is an amazing technology, almost magic-like. Serverless applications, like any other applications, require testing.
However, testing Serverless applications differs from traditional testing and introduces new challenges.
In part one, you learned why Serverless services introduce new testing challenges and my practical guidelines for testing Serverless services and AWS Lambda functions that mitigate these challenges.
In this post, you will learn to write tests for your Serverless service. We will focus on Lambda functions and provide tips & tricks and code examples by writing tests for a real Serverless application. In addition, you will learn my Serverless adaptation to the classical testing pyramid and implement it.
In part three, you will learn to test asynchronous event driven flows that may or may not contain Lambda functions, and other non-Lambda-based Serverless services.
A complimentary Serverless service project that utilizes Serverless testing best practices can be found in the AWS Lambda handler cookbook repository.
The Orders Serverless Service
We will use this sample service and write tests for its Lambda function handler.
Here's the architecture diagram:
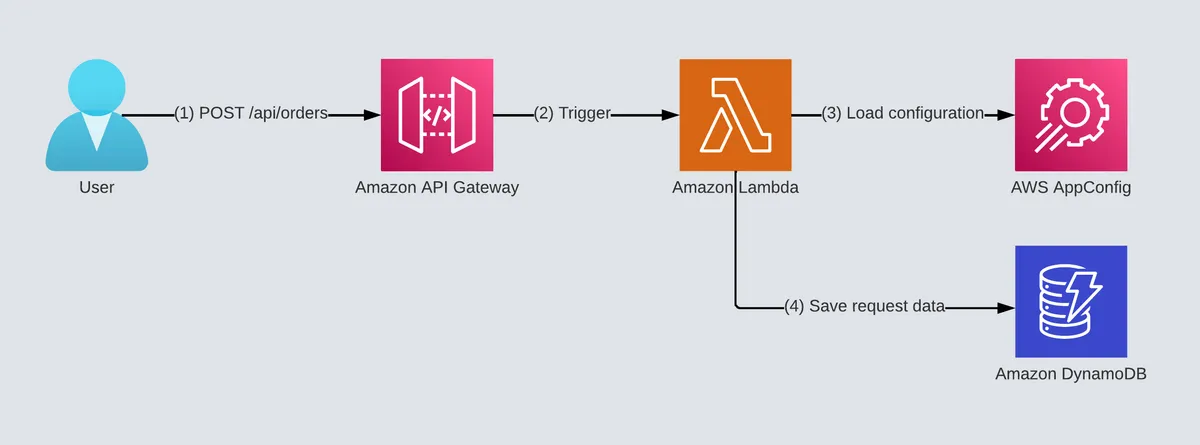
The 'order' service gets customers' orders for a single product type and saves the orders in the database.
This sample service is simple, an API Gateway that triggers a Lambda function that writes to a DynamoDB table. In addition, the Lambda function uses AppConfig for dynamic configuration and feature flags.
I use AWS CDK to deploy the order service.
I created this serverless template service that incorporated many best practices in the Serverless domain, from CI/CD and CDK to writing good function handlers.
Read more about it in the cookbook template project post and the project documentation.
The repository: https://github.com/ran-isenberg/aws-lambda-handler-cookbook
The Serverless Testing Pyramid
Assumptions
- The definitions below are not academic; they are my definition. The definition is not as important as the substance. As long as you test these aspects of your Serverless application, you can have confidence in your overall quality.
- While not mandatory, it's best you read the Serverless testing guidelines I presented in the previous post in the series.
- I use Python in the examples, but the principles are relevant to most Lambda-supported programming languages.
Let's go over the Serverless testing pyramid and understand the values and goals each step along the pyramid provides.
A Pyramid?
The "Test Pyramid" is a metaphor that tells us to group software tests into buckets of different granularity. It also gives an idea of how many tests we should have in each of these groups. Although the concept of the Test Pyramid has been around for a while, teams still struggle to put it into practice properly" - Martin Fowler
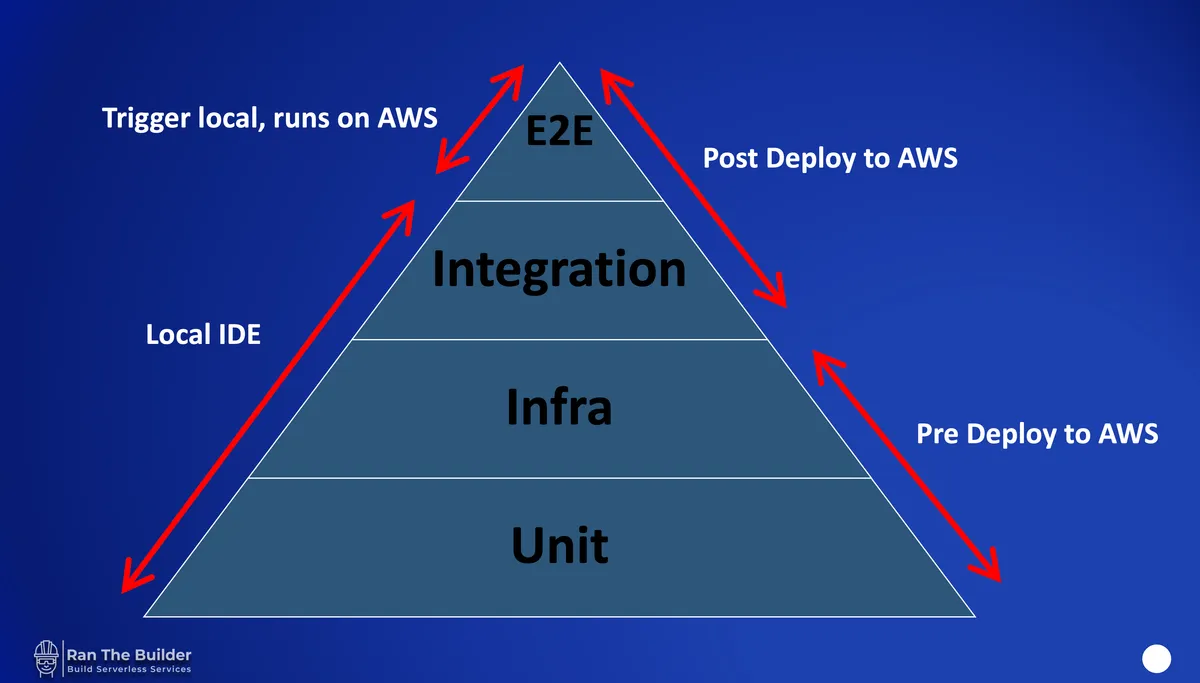
Let's make sense of this diagram.
The diagram defines four levels of tests: unit, infrastructure, integration, and end-to-end (E2E). Each test has its purpose and characteristics.
Following my Servleress testing guidelines, all tests are triggered in the IDE, and the developers can add breakpoints to their code.
Each test type gets its folder in the project structure under the main '/tests' folder.
As a side note, I use 'pytest' for Python-based applications for the testing engine.
Let's review the different testing types and their characteristics.
Unit Tests
Unit tests test the functionality of individual units of code. These tests are meant to be quick, easy to debug in the IDE with breakpoints, and do not require deployment to AWS, thus making them isolated.
Unit tests come into play in the code you write, i.e., the Lambda function code.
I usually use them in two use cases:
- Schema validations logic - I use Pydantic for input validation and schema validation (boto responses, API responses, input validation, etc.) use cases. The Pydantic schema can contain type and value constraint checks or even more complicated logic with the custom validator code.
- Test small isolated functions or modules that have defined input and output. In this case, I want to test the specific logic of an inner function/module and verify its logic and side effects. If the function requires AWS API calls or deployed resources, stub the call or move the test to the integration tests. I don't recommend calling the handler itself at this point (it will be done as part of the integration tests), but only small isolated functions.
If you want to learn more about input validation best practices for AWS Lambda functions, read the Lambda input validation best practices post.
Unit Tests Examples
Let's write a unit test.
The orders service create order Lambda function expects a JSON document containing two parameters: 'customer_name' and 'order_item_count.'
Our schema defines 'customer_name' as a string of lengths between 1 to 20 characters long and 'order_item_count' as a positive integer.
Sample valid input looks like this:
The matching Pydantic schemas looks like this:
Now, let's write unit tests that check both valid and invalid input types:
The tests check as many error schema types error whether it's an incorrect type or value constraints.
The test in line 5 checks the constraint that the customer name is a non-empty string, as it expects the schema to raise an exception.
The test in line 21 checks that a non-integer order item count value raises an exception.
These tests might seem trivial, but the more logic and parameters you add to your schemas, the more it increases the possibility of a production bug.
"Input validation should be applied on both syntactical and Semantic level." - OWASP
The complete order service unit tests are on GitHub.
Infrastructure Tests
As stated in the guidelines in my previous Servleress testing post, the application code and infrastructure reside in the same project and are deployed together.
Once your code and infrastructure are deployed, and there's no turning back.
So, we want to ensure our infrastructure is configured correctly, that there are no missing resources (IaC frameworks have bugs, too), and that we have no security issues.
We want to verify these aspect before deployment, so we don't disrupt our production environment.
As I'm more familiar with tools that use CloudFormation, I will provide testing tools based on it. The infrastructure tests will go over the CloudFormation template that we are about to deploy and check for numerous issues:
- Missing critical resources - a bucket/DynamoDB table/etc. was removed by mistake.
- Logical ID change of stateful resources - when a logical ID of a resource changes, the previous resource is deleted and the resource is recreates again. For stateful resources, such as DynamoDB, data loss can occur.
- Security issues - verify that role definitions are least privileged and resource configurations are secure: encryption at REST, no public S3 buckets, and more.
For AWS CDK-specific infra tests example, head over to my AWS CDK best practices blog and check out the "AWS CDK tests" section and the "Security Defaults are Not Good Enough" section.
For AWS SAM, check out their linter.
For generic CloudFormation templates, check CFN-NAG.
Infrastructure Tests Examples
Let's define a CDK security infrastructure test. The test covers our serverless service definition, from API Gateway to Lambda role and function and DynamoDB table.
Line 14 synthesizes the CloudFormation template, and line 11 runs a set of tests defined by the AWS solution matrix. An exception is raised in case of a security issue.
You can add more security standards; see the CDK Nag rule packs documentation.
Now let's define a CDK infrastructure test that verifies that our critical resource, the API Gateway, is defined and has not been deleted by mistake or bug.
Line 13 synthesizes the CloudFormation template, and line 16 asserts that there's an API gateway resource. You can expand this test, verify logical ids of stateful resources, and ensure they have not changed.
For other AWS CDK best practices, check out my other post.
The complete order service infrastructure tests are on GitHub.
Integration Tests
Integration tests are the bread and butter for Lambda function testing.
They test your code and how it integrates and interacts with the infrastructure you created on AWS. You test your Lambda function, a complete software module, either a micro or nano service, from start to its invocation end.
As such, integration tests require the deployment of your resources to AWS, and they typically:
- Run after the deployment phase in the CI/CD pipeline.
- Run locally in IDE, allow to debug with breakpoints.
- Run locally in IDE under the developer role and permissions, not the Lambda role.
- Call the function handler with a generated Lambda function event to simulate a real Lambda integration invocation.
- Require to set up local environment variables, hooks, or mocks required by the function at the beginning of the test (see conftest for Python).
- Can call AWS services APIs and resources.
- They are typically slower and less isolated.
- Make up the majority of the service tests.
- Contain tests for edge cases with mocks (mock failures or raised exceptions).
I mentioned in item 4 that you should generate the expected function event. There are at least three options I can think of for finding out the event schema sample:
- Generate it on your AWS account, print the event, and copy-paste it into a factory function that returns it for the integration tests.
- Use the aws-lambda-events schema repository. It contains an absurd number of sample event schemas.
- Read the documentation of the service that invokes your Lambda function. While not perfect, many AWS services have improved documentation and now include sample events.
Where to Start
I usually develop a new Lambda function handler by writing a "happy" flow input integration test that calls my new function. The happy flow simulates a real business use case and input. That way, I can debug my code locally until the test passes and use real AWS resources, aka TDD style.
Other tests should simulate (with mocks) the following use cases:
- Errors from AWS APIs - verify that we handle the errors correctly, perhaps even retry the action and not crash.
- Raised exceptions in internal layers, verified that they are captured, and the function's response is correct (Internal server error code for HTTP, etc.).
- Invalid input - verify an HTTP Bad Request response code is returned (when the function is behind an API Gateway).
- Feature flags configuration - I've written a post about how to handle testing with feature flags; read the managing Lambda feature flags post.
- Assert function side effects occurred correctly - did your function save an item to the DB? did it contain the expected parameters?
Integration Tests Examples
Let's write an integration test for our 'create order' API Lambda function. The Lambda takes an input event, parses it and saves it to a DynamoDB table.
Let's take a look at the Lambda handler we wish to test.
The Lambda handler will receive the input, verify the configuration, validate the input, and call the logic layer to create the order. Here's a snippet of the handler's signature:
View the complete handler code on GitHub.
Now, let's start writing the integration test.
In Python's pytest, we can use conftest files to define fixtures that run before any test module and set global mocks or environment variables that our Lambda handler requires.
We set numerous handler environment variables that the logger, tracer, and feature flags need. In addition, line 18 defines the variable for the DynamoDB table name that we save orders to. In the CDK code that defines the table, I set the table name as a CloudFormation stack output so it can be loaded up as an environment variable in the test in an effortless manner. It's a nice trick, and I recommend you do that for all environment variables you need to load up in the integration tests.
In line 21 we create a fixture that will inject the DynamoDB table name as an argument to our handler test.
Now, let's take a look at the some of the integration tests of this handler.
Look at the first happy flow test - 'test_handler_200_ok' in line 10.
When the create order handler receives a valid event, we expect it will write it to the DynamoDB table and return HTTP 200 OK code.
Line 13 creates a sample valid input payload of the API.
In line 14, we trigger the create_order Lambda handler with a generated event that contains the valid input and the other API Gateway metadata attributes. We can now add breakpoints to the handler, debug our logic, and ensure the tests pass.
The event generation factory method 'generate_api_gw_event' creates a complete AWS API Gateway event with the test payload and can be found in the test utilities module on GitHub.
Once finished successfully, the test asserts in lines 16-20 that the response schema is valid and contains the expected values.
In lines 22-26, we get the inserted item from the DynamoDB table and verify that the function wrote the item correctly to the table. The table name was populated as an argument to the test (as we saw in the conftest 'table_name' fixture).
Real AWS Services vs. Mocks
One significant advantage we gain by running the tests locally with Pytest but against real AWS resources is that we can mock almost anything. In the second test, 'test_internal_server_error,' we mock the AWS boto Table resource and simulate a DynamoDB client error when we fail to save an item to the database. This simulation allows us to test our retry code and dead letters queue strategy and verify that the function's return value, in this case, is HTTP 500.
In line 33, we mock the inner function in the logic layer of the function that creates a 'boto' Table resource. The mocked function will raise an exception when called.
Line 37 asserts that the exception was handled correctly, and in line 38, we assert that our mock function object was called to make sure it was the one that raised the exception.
We can choose to mock whatever internal logic we wish to break. We can use real AWS resources and mock only some of them, depending on your logic. Ultimately, you'd want to cover all use cases where you handle exceptions or errors and mock API calls with failures.
Code coverage utilities can help you make sure you cover your bases. However, they don't guarantee that your handler really works. You must simulate real business use cases.
View the complete integration test on GitHub.
End to End Tests (E2E)
The end-to-end tests aim to run against the deployed resources, simulate real customers' use cases, and trigger and event driven process across your architecture.
You want to ensure your infrastructure is configured correctly, that the event traverses between AWS resources correctly, that your AWS Lambda functions run with correct environment variables, and that their roles are configured with all the required permissions.
We will generate locally in the IDE the starting event and verify the responses.
From there, the entire process runs on your AWS account, and we have zero control over it. As such, these are the slowest tests to run as they test the entire chain from start to end on the infrastructure.
Please note that we don't have any option to mock failures, so I'd recommend testing only customer happy flows and security-related tests (more on that later).
We will not poll or call AWS resources directly but use API calls, the same as the customer would. We must send a REST API call to the API Gateway and assert its response. Any side effect was already tested and proved to be working in the integration tests that use REAL AWS services, so there's no need to retest it other than to assert Lambda's response. To put it in context, in the order service, when creating a new order, verify that the response is valid and contains values as expected. However, don't check the DynamoDB table directly for the inserted item, but use customer facing REST APIs - a 'get order' API (it does not exist yet in my example but you get the point) to check the item was inserted.
In part three of this series, I will discuss how to test Step Functions and async services, but for now, let's focus on the synchronous flow of the order service.
E2E Tests Examples
Let's take a look at the end to end tests below:
In line 15, we start the happy flow of a user creating a valid order request.
We find the full URL of the service with the stack-output mechanism we did in the integration test for the table name.
Line 17 generates the valid input payload.
Line 18 sends a POST REST API request to the API Gateway.
Line 19 asserts the response code from the function, and lines 21 through 23 assert the response data.
In line 26, we test the correct handling of invalid input.
We send in line 28 a malformed payload (does not match the schema) and expect in
lines 29-31 to get an HTTP BAD REQUEST status code with an empty JSON body.
View the complete E2E test on GitHub.
Debugging E2E Tests
Integration tests can pass, but the E2E variation of the test can fail due to misconfigured role permissions, missing imports in the Lambda function ZIP package, missing environment variables, and other "fun" use cases.
The only way to debug them is to open the good old AWS CloudWatch logs, view the error, deploy a fixed version, and rerun the test.
Want to learn the Lambda function logging best practices? Check out my Lambda logging best practices post.
Security Tests
It's essential to test your authentication and authorization mechanism. Usually, these mechanisms are implemented with a custom Lambda authorizer, IAM authorization, Cognito authorizer, or custom code in the function handler that does both.
These mechanisms (all but the custom function code) are configured in the IaC part (CDK, SAM, etc.), and it is critical to ensure they are configured correctly and were not deleted by accident.
So, It's important to invoke the function with invalid permissions and ensure the function/API Gateway returns the correct HTTP 40X response. It would be best if you simulated the following use cases:
- Call your function with an invalid token (expired token).
- Call your function with a valid authentication token (log in as a test user) but with invalid permissions (the user is not allowed to execute the API but is logged in to the system).
Please note that I did not include any authentication/authorization mechanisms in my sample' order' service as it would have complicated the example.
Read the IAM production security best practices.
Performance Tests
Monitoring your Serverless service performance and fine-tuning it from a cost/performance aspect regarding expected customer traffic is essential.
It would be best to run these tests occasionally and at least once before GA productization. These tests provide insight into service bottlenecks and hidden connections and allow you to configure better reserved or provisioned concurrency values for your service.
Utilizing tools such as AWS X-Ray, AWS Lambda Power Tuning, and AWS Lambda Powertools tracer utility is recommended. Read my Lambda observability best practices post.
You can find more Serverless productization readiness tasks in my serverless productization checklist post.
The Testing Pyramid & CI/CD Pipeline
My recommended Serverless CI/CD pipeline will run unit and infra tests, then deploy the application to AWS and run integration and e2e tests.
Failure in any of the steps acts as a gate that fails the entire pipeline and stops it from continuing to the next step.
For a Serverless CI/CD pipeline based on GitHub actions and CDK read my GitHub Actions and CDK deployment post.
Summary - Why Does This Work?
I've listed the Serverless testing challenges in part one of the series. By following the guidelines I presented there and by implementing the Serverless testing pyramid, we were able to mitigate most, if not all, of the Serverless testing challenges:
- We provide good developer experience; we can run the test from the IDE and debug locally with integration & unit test.
- We automate all our tests.
- We gain confidence that our code will work in E2E because we use actual AWS services even in integration tests.
- We test both our infrastructure configuration and service code in the tests.
- We cover both infrastructure, performance, and cost aspects in our tests.
- We run the entire even-driven chain of events from beginning to end.
- We mock failures in both our logic and AWS API calls.
- We cover input validation aspects.


