

In this post, you'll gain practical knowledge of how SQS FIFO works from a detailed perspective. You'll learn to achieve the highest possible throughput and configure it correctly with CDK TypeScript code examples.
SQS Brief Introduction
The Amazon SQS (Simple Queue Service) isn't "simple" in terms of how you can decouple the components of a cloud application or how it can scale. SQS offers a secure, highly available, and reliable distributed queue system for asynchronous message storage and processing. It provides configurable message lifecycles and guaranteed delivery through redundant storage across multiple availability zones.
While SQS provides many beneficial features, it generates some challenges due to two inherent limitations:
- No Guaranteed Order: Messages may arrive out of order, requiring developers to manage ordering.
- Potential Duplicates: Messages might be delivered more than once, necessitating idempotency handling.
To overcome those limitations, we can use another SQS flavour: the SQS FIFO (first in, first out).
FIFO SQS
FIFO (First-In-First-Out) queues have all the capabilities of standard queues. They are designed to enhance messaging between applications when the order of operations and events is critical or where duplicates can't be tolerated.
FIFO allows handling messages as your favourite coffeeshop line, respecting the message ordering and removing message duplication.
Like everything else, it is not a plug-in feature, and it has limitations/quotas, like being slower and more expensive than regular SQS queues.
Sending and Receiving Messages
When working with FIFO SQS queues, it's essential to understand Message Deduplication ID and Message Group ID.The Message Deduplication ID is a token that prevents SQS from sending the same message multiple times. If a message with a particular deduplication ID is sent successfully, other messages with the same ID are accepted but not delivered again within a 5-minute window. That is how SQS FIFO removes the duplicate messages limitation.
The Message Group ID tags a message belonging to a specific group. Messages in the same group are processed one at a time in order, but messages from different groups might be processed out of order. That is how SQS FIFO removes the messages out of order limitation.
As displayed in the image below, if you fire off many messages with unique IDs to a FIFO queue, Amazon SQS will line them up and handle them in order. Messages with the same group ID are stored and processed as they come in. To keep things neat, each sender should use a unique group ID. Just remember, if you don't tag your messages with a group ID, Amazon SQS won't play ball.
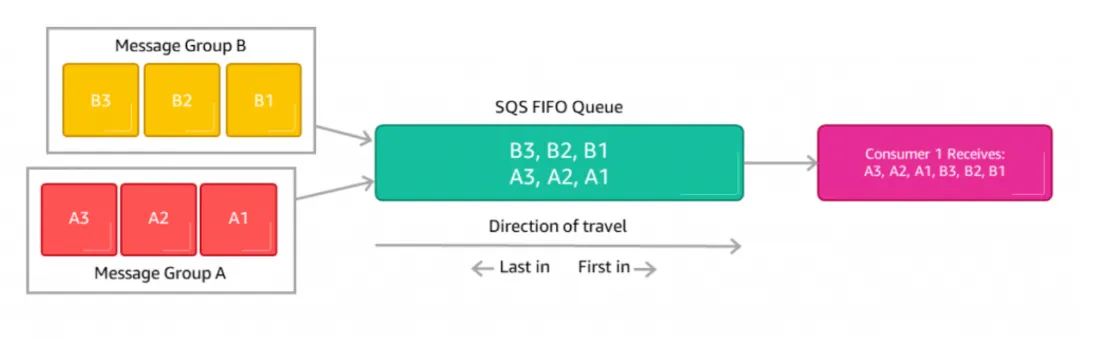
Keep in mind that you can't directly ask for messages with a specific group ID on the message receiver end.
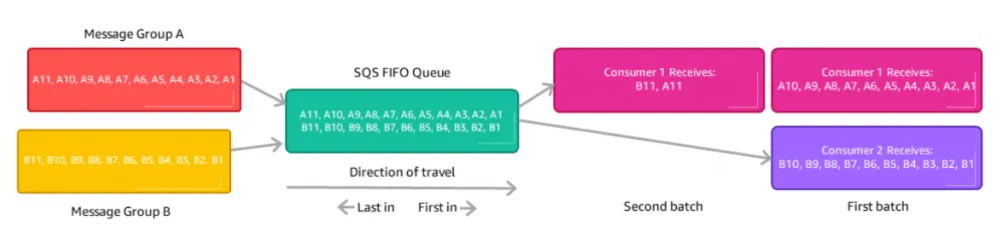
When you pull messages from a FIFO queue with multiple group IDs, Amazon SQS tries to give you as many messages from the same group so other consumers can grab different groups. Once you get a message from a group, only more from that group come your way.
You can receive many messages at once, keeping their FIFO order, but if there aren't enough from one group, you'll get some from another as seen in the image below where Consumer 1 gets both A and B group messages in the second batch. Batches have a maximum size of 10 messages.
Limitations
Before we get started, it's important to keep in mind that there is no silver bullet, so we must address two limitations before implementing.
Performance
The first limitation is performance. Supporting exactly-once and in-order message delivery may significantly impact FIFO queue performance, potentially creating a bottleneck in your application. FIFO queues have a lower throughput than standard queues, with a default limit of 300 transactions per second (TPS). However, batching can increase this limit to 3,000 TPS.
You must always be aware of performance limitations to handle them effectively. For instance, create the message group ID carefully, as messages with the same message group ID will be returned in order. While this is intended behaviour for a FIFO queue, remember that only once a message has been removed from the queue will the following message with the same message group ID be returned.
Message De-duplication
The second limitation is message de-duplication. Content-based deduplication is possible with FIFO queues, which remove duplicate messages within 5 minutes. This time frame cannot be changed, so applications relying on message deduplication should be aware of this restriction.
High-Throughput Real World Scenario
We were implementing a messaging system to inform our clients about lab test results, so we needed these messages to follow a specific chronology. Imagine receiving a series of messages without chronological context; it would be quite a mess. Therefore, SQS wouldn't be ideal for our case, so we opted for FIFO. However, it wasn't all smooth sailing.
Since we have thousands of clients and thousands of messages for each client, we needed something fast. Given the performance limitations mentioned earlier, we had to rethink our entire setup. As FIFO can cause a bottleneck, we had to find a way to make it scalable. That's where High throughput for FIFO queues in Amazon SQS comes in.
FIFO SQS High Throughput to the Rescue
First of all, this saved our day and helped us with our large volume of messages. Since there's no silver bullet, we must always be aware of our tools' limitations.
High-throughput FIFO queues in Amazon SQS handle many messages while keeping strict orders, which is perfect for high-demand order processing. However, they're only necessary if message order is crucial or the message volume is low. Standard queues are simpler and cheaper for small-scale or infrequent messaging.
For details on message quotas and data distribution strategies, check Amazon SQS service quotas.
Partitions and Data Distribution
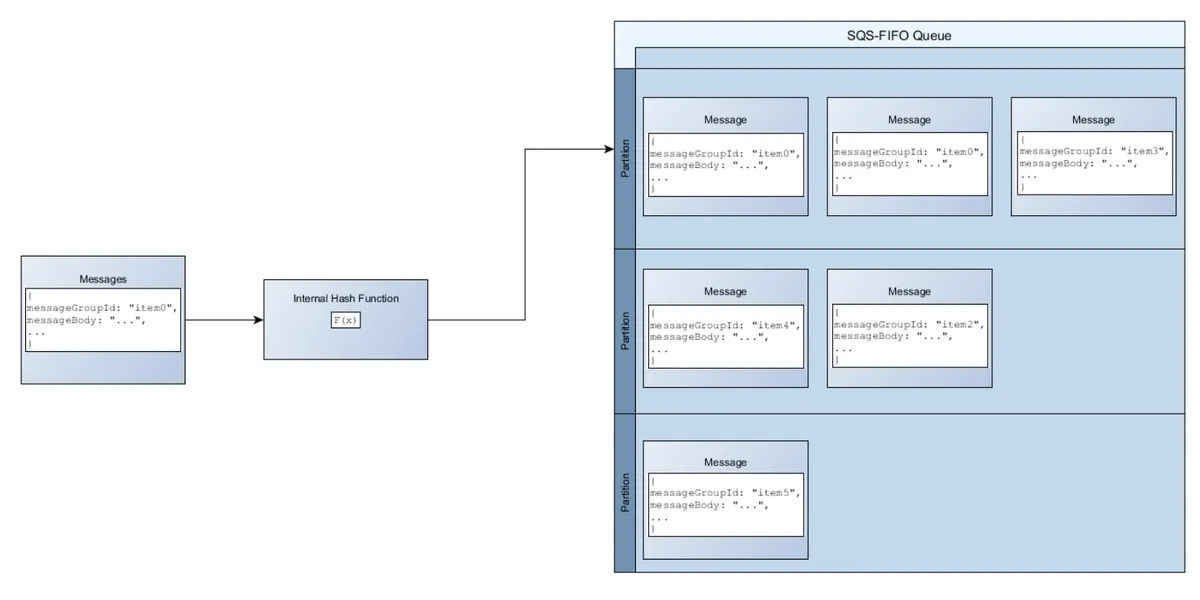
Amazon SQS stores FIFO queue data in partitions, automatically replicated across multiple availability zones within an AWS Region. You don't manage these partitions, Amazon SQS does it for you.
For FIFO queues, Amazon SQS adjusts the number of partitions based on demand:
- If the request rate is high, more partitions are added to the regional quota.
- If utilization is low, partitions may be reduced.
- This management happens in the background, always keeping your queue and messages available.
When adding a message to a FIFO queue, Amazon SQS uses the message group ID with a hash function to determine which partition stores the message. Messages are stored in the order they arrive, with their location based on the hash value of the message group ID.
Increasing the number of message groups will potentially boost the number of partitions and throughput in high-throughput SQS FIFO queues.
Coding Example
Let's set up our FIFO SQS queue with high throughput enabled using CDK and Typescript.
First, we'll set our queue and then write code for the message producer:
Line 10: We must provide the suffix ".fifo"; otherwise, it will fail when you deploy.
Line 11: This parameter must be true to set up our fifo.
Line 12: Here, you will configure your high throughput and specify whether message deduplication occurs at the message group or queue level. For instance, if you need to have multiple deduplications based on each message group, this is where the magic happens. Otherwise, you can find some issues, as the default is set to the entire queue.
Line 13: Specifies whether the FIFO queue throughput quota applies to the whole queue or per message group. Set this as PER_MESSAGE_GROUP_ID, the required settingfor using high throughput for FIFO queues
Line 14: This was set as false because in this example we are not using a well-defined message content, however, if it's your case you can set it as true.
Now, let's produce messages:
Line 11: This line configures message attributes (Title and Type) for specific metadata associated with the message content.
Line 21: Specifies a unique MessageDeduplicationId to ensure duplicate messages are correctly identified and processed in the FIFO queue.
Line 22: Defines a MessageGroupId to group related messages (blood-test results) that must remain in order during processing.
Tips & Tricks
Now that we understand the fundamentals let's explore some tips and tricks for writing FIFO SQS code that handles high throughput.
Message Producing & Deduplication
Let's review some considerations before sending a message to a high throughput SQS FIFO queue.
To set up deduplication, you can either enable content-based deduplication, which uses an SHA-256 hash of the message body. This method can be tricky and might not work as expected if there's even a tiny difference, like an extra space, in the message.
Alternatively, you can provide a message deduplication ID yourself. This is especially useful if you're working with a message chat provider like WhatsApp, where sending different messages to the same person often requires a unique ID for each message group ID.
In the first use case, if your app sends identical message bodies and provides a unique deduplication ID for each message, you must choose carefully.
On the other hand, if your app sends unique message bodies, enable content-based deduplication.
Lastly, no changes are needed for consumers, but if processing takes a long time, add a receive request attempt ID to each ReceiveMessage action to handle retries and prevent queue pauses due to failed attempts.
Prefer Batch APIs
As FIFO is slower than regular SQS, we must consider batches when receiving messages.
The maximum batch size for FIFO queues is 10 records. Processing using this limit significantly boosts performance, nearly 10 times better than setting the SQS FIFO queue to batchSize: 1.
Reduce Cost
The default behaviour for SQS FIFO is to deduplicate messages across the entire queue.
If you want to deduplicate messages within each Message Group ID, you must enable the High Throughput mode, which can be costly. To save costs, you can achieve a similar result by adding a prefix to the Message Deduplication ID when sending messages based on the Message Group ID, please remember that each group should be treated as one partition, so it's essential to consider your quotas accordingly.
Let's take a look at the code example below:
In lines 17 and 18, you can see where the change is set. This allows us to achieve deduplication per message group ID without incurring additional costs. For example, suppose you have different message group IDs for various types of communications, such as WhatsApp, emails, and SMS.
By assigning a unique message group ID to each type of communication, you ensure that messages within the same group are processed in order and without duplication. This approach helps by organizing messages logically and efficiently, preventing duplicates within each group, and maintaining the sequence of message delivery without the need for additional deduplication mechanisms, which could otherwise incur extra costs.
Failures & Retries
To manage failed and retry messages, it's important to ensure they are retried without concern for the order or the creation of new messages. If a message fails to be sent, the producer should resend it using the same deduplicate ID.
Once you get a message with a group ID, only more messages from that group will come your way once you handle it, or it will become visible again. For a comprehensive understanding of retries and failures, including the concepts of dead letter queues, refer to these detailed guides:
- Mastering Retries: Best Practices for Amazon SQS
- Effective Amazon SQS Batch Handling with AWS Lambda Powertools
- Amazon SQS Dead Letter Queues and Failures Handling Best Practices
General SQS Tips
Lastly, I highly suggest you check out AWS's own SQS best practices article.
Conclusion
Like everything in life, we need to analyze our case, think about best practices, and be skeptical that things work the first time; we always need to consider the worst-case scenario when designing a solution.
We must always be frugal because this is a quality, not a development case defect. We need to have a mind aligned with the need for scale today. Everything is scaled, and everything can be consumed massively, so we need our systems to have more and more flexibility but without neglecting the resilience and security of our applications; because of this, I decided to condense everything I've learned through hard work poring over piles of articles and documentation, this post was created with a lot of sweat and tears.
Happy queuing, and may your messages always arrive on time (and in order)!


