

In this two-post series, you will learn to monitor serverless services with CloudWatch by building dashboards, widgets and alarms with AWS CDK.
In this post, you will learn what it means to monitor a serverless service, why it is essential, and how to build CloudWatch dashboards to monitor your serverless service with widgets. The widgets display information from CloudWatch logs, metrics, custom metrics, and define CloudWatch alarms as part of a proactive approach.
In the second part of the series, we will use AWS CDK to monitor a sample serverless service and build the dashboards presented in the first post in the series.
What does Monitoring Serverless Applications Mean
So you've built your serverless service and went live in production. Great!
However, nothing is bulletproof, and it's just a matter of time until a bug or production issue will surface.
"Service Health" is an expression that refers to the operational status, availability, and performance of a service, ensuring it is functioning correctly and providing its expected user experience. That is why we need a monitoring solution that provides visibility crucial to understanding our service's current and future health status. That's where CloudWatch dashboards come into play. They are an essential serverless service health monitoring solution.
The dashboards make it easy to understand the current service status and react accordingly.
CloudWatch service health dashboards display different information in widgets. Each widget displays either CloudWatch logs, alarms, or custom metrics information.
CloudWatch provides numerous metrics for many serverless services out of the box, but logs and custom metrics require specific implementation. If you want to learn observability best practices, check my previous blogs about tracing, logs, and metrics:
Where to Start
Our ultimate goal is to discover any potential problem, whether a bug or configuration issue resulting in performance degradation before any customer is aware or affected by the issue.
We want to monitor performance and errors. Performance monitoring is achieved with CloudWatch metrics. Errors can be monitored with both CloudWatch metrics and service logs. And lastly, CloudWatch alarms will contribute to the proactive approach and alert us of any looming catastrophe.
When building a new monitoring dashboard for a service, I follow these guidelines:
- Identify the critical flows in your service and analyze their serverless components and Lambda functions. Try to think: how can I know if my critical flow is about to break or has errors? Can I use specific log messages or metrics?
- Open CloudWatch console metrics explorer - look for metrics that CW provides out of the box for each serverless service that belongs to your critical path. Think carefully about which metrics provide the most insight for quick error resolution.
- Identify whether the critical paths are read/write only. There are different metrics for read/write operations in DynamoDB and other serverless databases. Focus on the metrics that are important for you.
- Information overload - try to refrain from adding all the possible metrics. A dashboard with too much information is a dashboard that nobody uses. Dashboards need to be simple and easy to use. A simple glance should provide you with the information you need.
- Tailor the dashboard or dashboards to the persona that uses it. I will present a multi-layered dashboard approach - more on that below.
- Manage the monitoring dashboard with infrastructure as code. Managing them with code makes them reusable across multiple teams and services. In addition, if they get deleted by mistake, you have a safe method to restore them.
- Define CloudWatch alarms on critical issues (more on that later).
- Use dashboard colors to emphasize information type: errors such as red etc.
Now that we understand the theory, let's turn theory into practice and monitor a sample serverless service, the 'orders' service.
The Orders Serverless Service
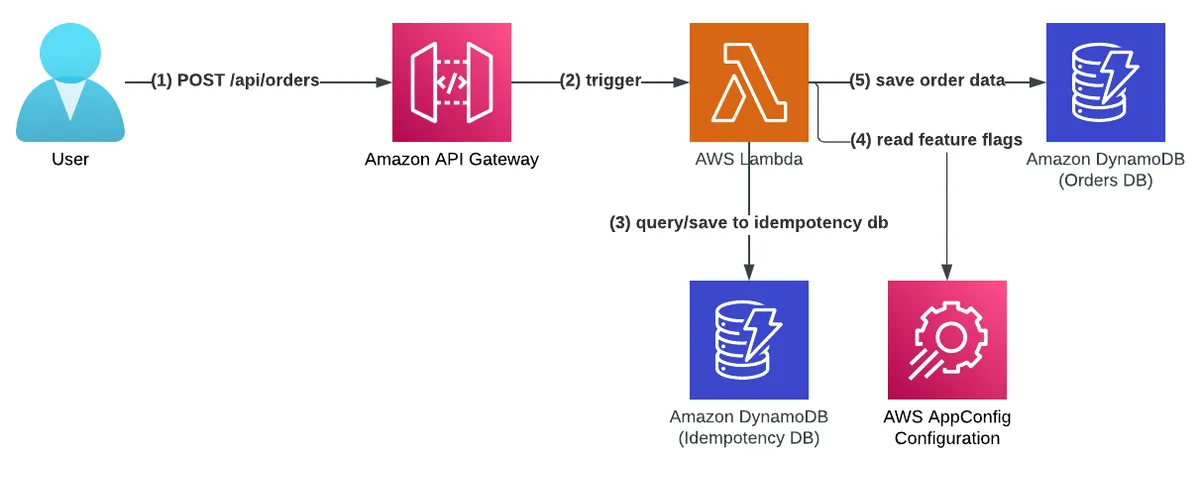
The 'orders' service provides a REST API for customers to create orders of items.
The service deploys an API Gateway with an AWS Lambda integration under the path '/api/orders/' and stores orders data in a DynamoDB table. It has advanced features such as idempotency (read more about it in my API idempotency blog post) in the form of a second DynamoDB table and features flags capabilities with AWS AppConfig (read more about it in my feature flags best practices post).
You can find the complete code in the AWS Lambda handler cookbook repository.
Let's analyze the critical path of the service.
The critical path is the 'create order' Lambda function. We understand that our critical path is writing orders to the DynamoDB table, so we need to monitor DynamoDB write metrics and monitor API Gateway error rate. In addition, we want to make sure our customers have good experience so total operation time monitoring is essential.
Building CloudWatch Dashboards
Different service personas use monitoring dashboards for various reasons.
Let's review our personas:
- Site reliability engineers/ support teams require information to quickly diagnose service problems and fix or escalate them to the development team. SREs/support teams are familiar with the service at the higher level (but sometimes at a deeper level) and, in many cases, are in charge of multiple services.
- Service developers - the team that builds and maintains the service. They are the service experts.
- Product team members - interested in knowing whether the users get the promised user experience. They monitor KPI metrics to understand service usage.
As you can see, three personas see view and monitor the service differently. As such, we will build multiple dashboards to cater to their responsibilities and requirements.
We will define two dashboards: high-level and low-level.
High Level Dashboard
This dashboard is designed to be an executive monitoring overview of the service.
The dashboard provides a simple overview that does not require a deep understanding of the service architecture.
In our case, it focuses on AWS API Gateway metrics for both overall performance (latency) and error rates (HTTP 4XX or 5XX response codes).
API GW latency is defined by "the time between when API Gateway receives a request from a client and when it returns a response to the client" - AWS docs.
This metric marks the total time it takes for a user to create an order and get a response back. Note that we monitor average, P50, P90 and P99 percentiles metrics - more on that later.
KPI metrics are also included in the bottom part, which will cater the needs of the product teams. They tell the story of user usage, which is critical to the service's success. In our service, a KPI metric was defined as the number of valid 'create order' requests.
Personas that use this dashboard: SRE, developers, and product teams (KPIs)
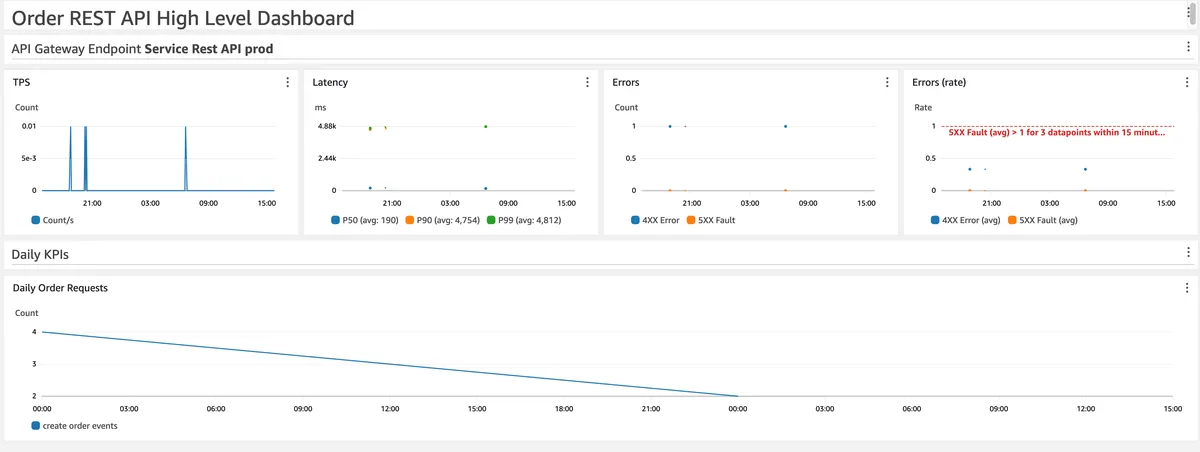
Please note - you can add a log widget that filters only 'Error' messages. I chose to add it at the low level dashboard.
In addition, I have defined CloudWatch alarms regarding the API Gateway error rate (as noted by the red line 5XX fault rate in the errors rate widget), but more on that below.
Low Level Dashboard
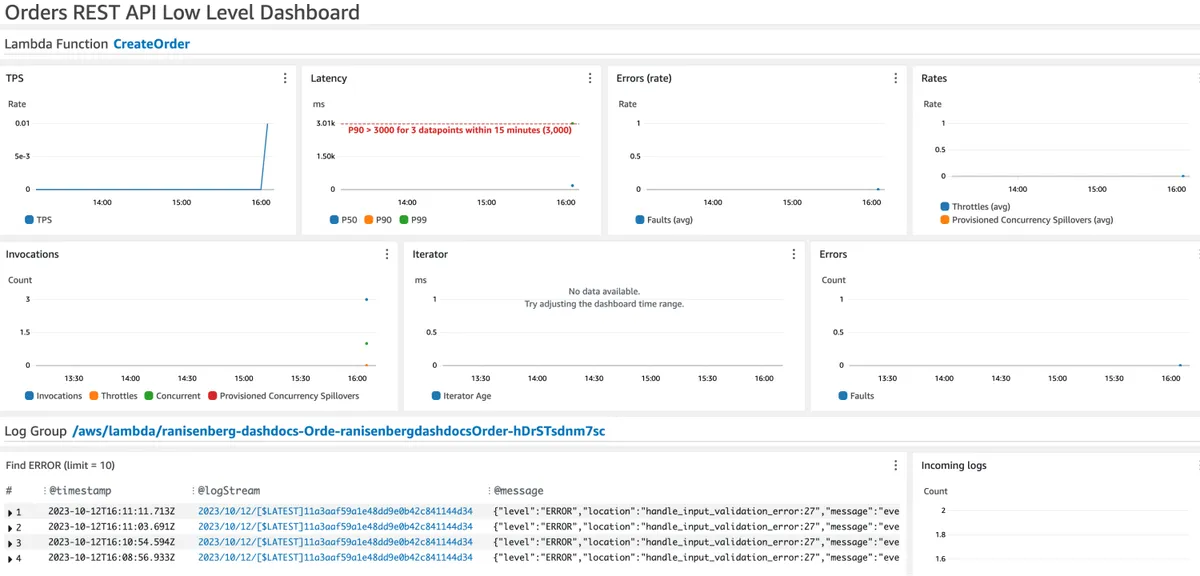
The second dashboard we built provides a deep dive into all the service's resources: their metrics and logs. As such, navigating through the dashboard widgets requires a better understanding of the service architecture.
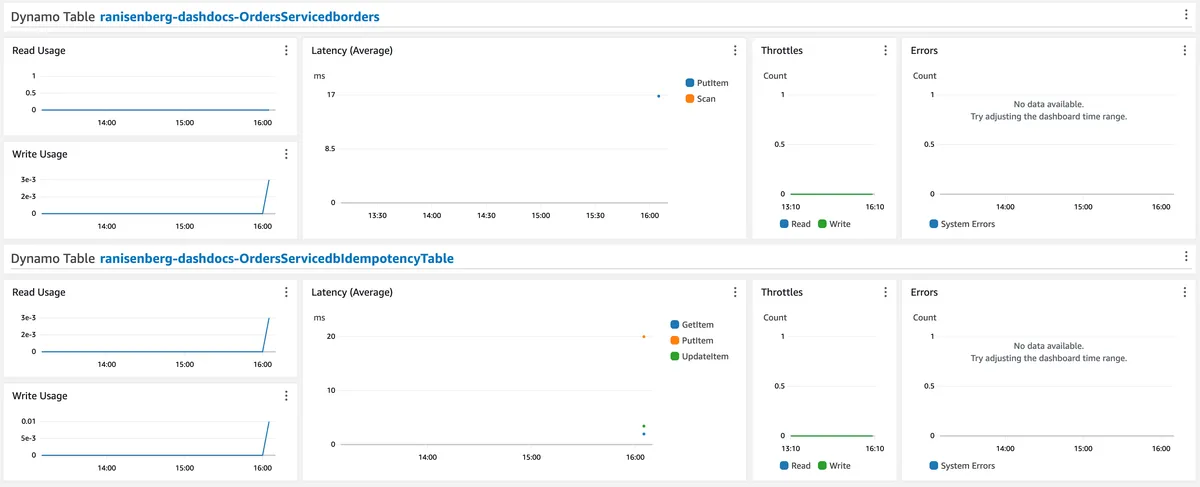
The dashboard displays the Lambda function's ('create order' function) metrics for total duration time (it is labeled as latency, but it's duration), errors, throttles, provisioned concurrency, and total invocations.
In addition, a CloudWatch logs widget shows only 'ERROR' logs from the Lambda function. Each log will contain a correlation ID that helps to find other logs from the same session when debugging an issue.
As for the DynamoDB tables, we have the primary database and the idempotency table.
We monitor them for usage, read/write operation latency, errors, and throttles.
Personas that use this dashboard: developers, and sometimes SREs.
Average Duration Does Not Tell it All
Average duration does not tell the real story of duration.
It is a game of numbers. On average, the duration of 'create order' function may be acceptable for all users, but for some users, perhaps a tiny percentage, the duration might be terrible. That's where percentile metrics comes into play - metrics for P99, P90, etc.
Let's take P99 for example:
the 99th percentile (abbreviated as p99) indicates that 99% of the sample is below that value and the rest of the values (that is, the other 10%) are above it - Abstracta US
That means 1% of your users might get a bad user experience. It might sound not that bad, but in the context of a billion-user company such as Facebook, that translates to millions of frustrated users.
CloudWatch Alarms
Having visibility and information is one thing, but being proactive and knowing beforehand that a significant error is looming is another.
A CloudWatch alarm is an automated notification tool within AWS CloudWatch that triggers alerts based on user-defined thresholds, enabling users to identify and respond to operational issues, breaches, or anomalies in AWS resources by monitoring specified metrics over a designated period.
In our dashboards, you will find examples of two types of alarms:
- Alarm for performance (duration or latency) threshold monitoring
- Alarm for error rate threshold monitoring
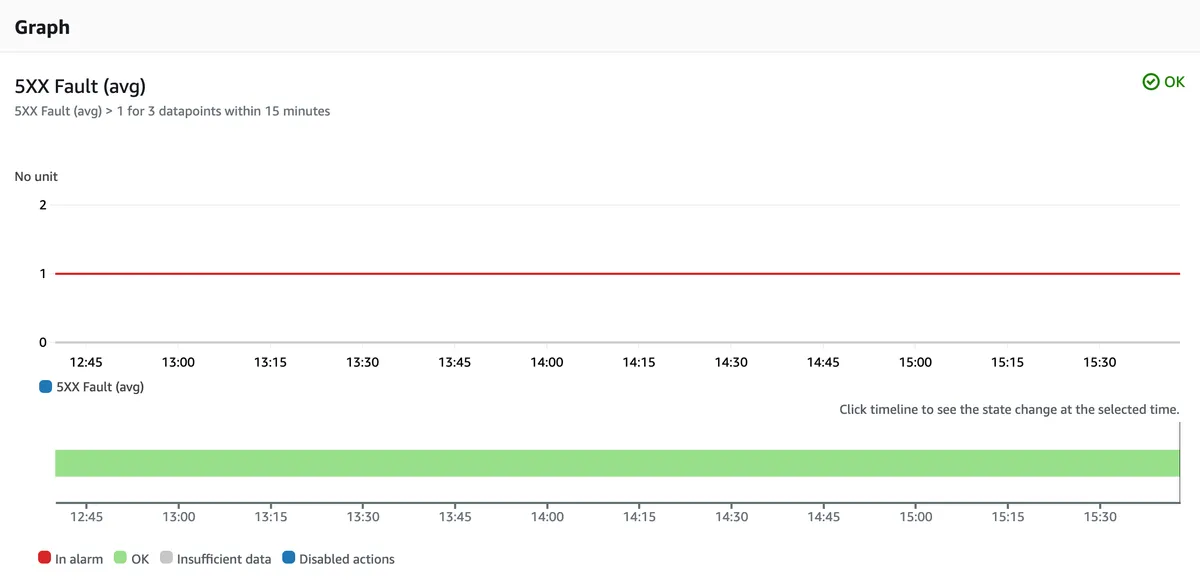
Error Rate Alarm
HTTP code 5XX means an internal server error. This error should never happen. It is a sign that something unexpected has occurred; it might be an AWS outage/issue or a bug in the code.
I have defined the threshold here as one 5XX error over the course of 15 minutes, but you can define it as you please (I might have been too strict).
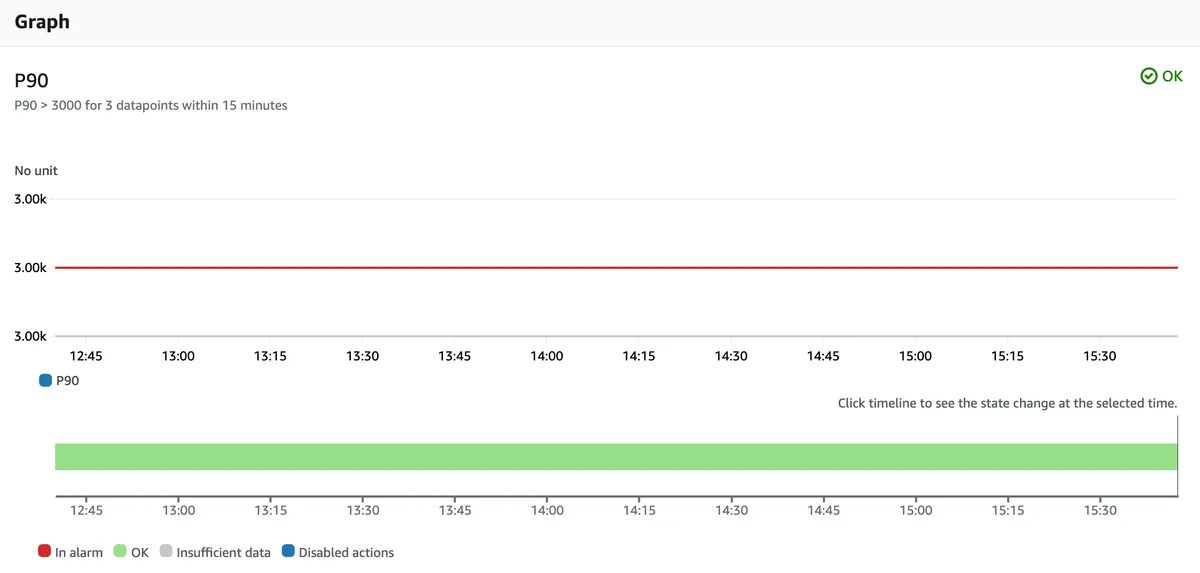
Duration Based Alarm
For duration-based issues, we define the following alarm on P90 duration for the 'create order' Lambda function. The average duration Lambda function 'create order' is 2 seconds, so I set the alarm's threshold at 3 seconds (3000 ms). Please note that you should cover other distributions, not just P90 - P99, P95, and average, if you wish to provide the best user experience to ALL your users.
Please not that you can change the widget to display a singular numerical value instead a graph.
Alarms Actions
Alarms are of no use unless they have an action when they trigger.
We have configured the alarms to send an SNS notification to a new SNS topic. From there, you can connect any subscription - HTTPS/SMS/Email, etc. to notify your teams with the alarm details so they can react and resolve the issue.
Reacting to Alarms
When we discover potential performance issues in serverless services, mainly Lambda functions, the solution differs from the one we had in the "old" world - you will not restart a server. You do not manage the underlying infrastructure, and each issue requires thorough research into the traffic volume, user input, and Lambda configuration.
In addition, each solution requires a CI/CD pipeline deployment, whether to update the function configuration or code (please do not make manual changes in production).
Summary & CDK Code
This concludes the first part of the monitoring post. We have covered what is serverless service monitoring, our methodology for building a dashboard, and we made a dashboard for a sample service.
In the second part of this blog series, we will go over the AWS CDK code that built these dashboards and alarms.
For those who want to view the code right now, view the monitoring construct on GitHub.


