

Now that AWS re:Invent 2023 is officially over, let's go over the exciting new services and features launched from a Serverless developer perspective.
The Keynote
This year, I attended DR. Werner Vogels' keynote in person, and it was quite the experience!
Vogels' keynote did not disappoint, and it was inspiring yet filled with humor as last year. However, if you expected some groundbreaking announcements, this was not the keynote for you.
Vogels discusses "The Frugal Architect" guidelines, which correlates to my blog post, the "Cloud Architect's High-Level Design Template". It is a crucial reminder for cloud architects, developers, and CFOs. Cost and sustainability are a critical part of every architecture.

As for the rest of the concepts he describes, Brooke Jamieson breaks them down quite nicely
in the following tweet: https://twitter.com/brooke_jamieson/status/1730350033818841250?s=46&t=OvUHU2nQc6B63nOcjfm1mA
One sentence though, hit hard:

I can't tell you how many times I have heard this sentence from developers in my lifetime.
Just because we always do something the same way does not mean we should keep doing it. Always look to improve and refactor.
The rest of the keynote focused on AI advancements and several announcements, which I covered below. The segment about AI saving children from child abuse was also a keynote highlight. I highly suggest you watch the entire keynote.
Let's review the most exciting new services and features for us serverless developers.
Start a Serverless Service with Three Clicks
This is a shameless self-plug :)
If you missed my breakout session with Heitor Lessa, "The Pragamtic Serverless Python Developer", the recording is live.
We discuss pragmatism for serverless Python development. We talk about project structure, writing Lambda handlers, integration code, testing synchronous and asynchronous flows, and provide open-source tools for optimizaing cold starts and writing documentation.
We also provide a full serverless service GitHub repo with production-ready features such as CI/CD pipeline with multiple environments (dev, stage, production), CW dashboards, observability, CDK code, and Cognito authentication.
And lastly, if you wish to start a serverless service using the same best practices, I have a template GitHub repository ready for use with just three clicks.
Elasticache Serverless
A new serverless option for Elasticache enables customers to create a highly available cache in less than a minute, supporting auto-scaling. Overall, this is a significant improvement over the current offering of ElastiCache. Elasticache is now more self-managed with automatic scaling, transparent engine upgrades, and security updates.
However, would you consider it "true serverless" when it comes with a mandatory VPC requirement and costs you a minimum of 90$ per month for idle time?
Khawaja Shams, one of the founders of Momento, who is one of the competitors of this new offering, offers his take:
Read the ElastiCache Serverless announcement.
SQS Improvements
Throughput increase and dead letter queue redrive support for Amazon SQS FIFO queues
Better scaling and improved performance are always good news. SQS now supports sending or receiving up to 700,000 messages per second with batching, which is an insane number.
SQS redrive support for FIFO SQS is even better. Before, it was supported only for regular SQS. Redrive is the ability to send a batch (usually of failed items) from an SQS (usually a DLQ) to another SQS via API.
If you want to learn more about redrive API and SQS best practices, check out my SQS DLQ best practices series.
Read the SQS FIFO throughput and DLQ redrive announcement.
CloudWatch Improvements
CloudWatch has declared several improvements, both before and during re:Invent.
Let's go over them quickly:
Use natural language to query Amazon CloudWatch logs and metrics (preview)
In the announcement, the author asks CW natively: "Tell me the duration of the ten slowest invocations" and CW generates a CW query out of it:

OK, that's quite impressive.
I've always found CW query languages a bit cumbersome, and this is a game changer - super easy. The author continues and shows that there's context to chat, and he updates the query to output fewer fields.
The original announcement can be found in the CloudWatch natural language queries post.
If you wish to learn more about CloudWatch logging best practices, read my CloudWatch logging best practices post and about CloudWatch dashboard building, read my CloudWatch monitoring blog post.
Automated pattern analytics and anomaly detection
Amazon CloudWatch has added new capabilities to automatically recognize and cluster patterns among log records, extract noteworthy content and trends, and notify you of anomalies using advanced machine learning (ML) algorithms trained using decades of Amazon and AWS operational data.
Read the CloudWatch automated pattern analytics announcement.
Log class for infrequent access logs at a reduced price
CW logs can get expensive at scale, and the new log class is a great way to reduce costs. However, you need to pay attention to what you lose. If you select this logs class, you cannot write EMF logs and transform them into metrics, breaking utilities such as Powertools for Lambda Tracer utility. You also lose the ability to subscribe to log events or export to S3.
If you wish to learn more about exporting logs, read my CloudWatch log export blog post.
If you wish to learn more about tracing best practices, read my Lambda observability blog post.
Read the CloudWatch infrequent access log class announcement.
StepFunction Updates
Two updates for step function but a highly coveted ones that improve the usability of StepFunctions.
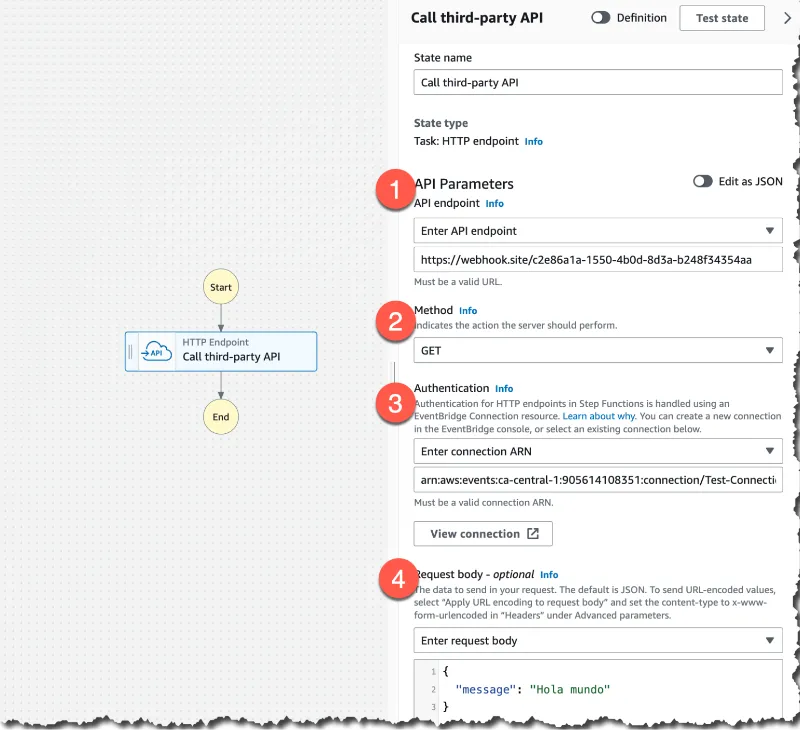
HTTPS Endpoints
The first, HTTPS endpoints are a new resource for your task states that allow you to connect to third-party HTTP targets outside AWS. Step Functions invoke the HTTP endpoint, deliver a request body, headers, and parameters, and get a response from the third-party services. You can use any preferred HTTP method, such as GET or POST.
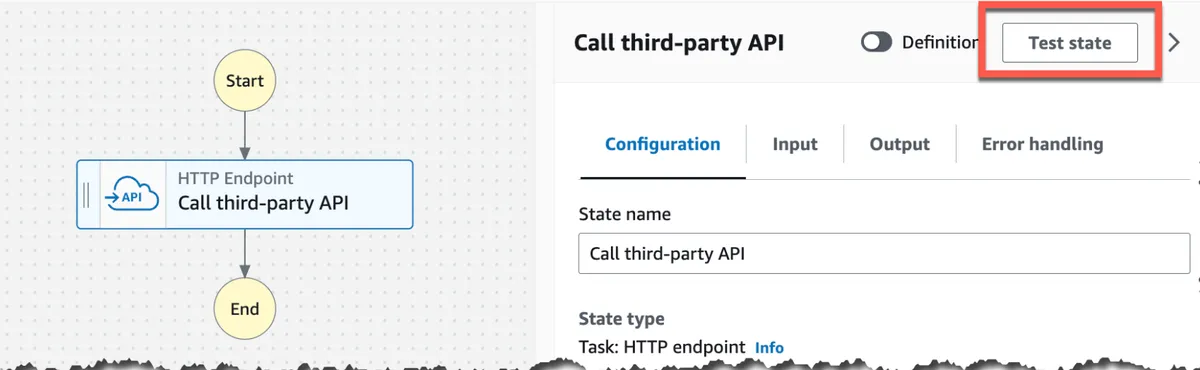
Test State
The ability to test a specific step with simulated input and check its output significantly improves the developer experience for those who use the console to design their step functions.
Read the Step Functions endpoints and test state announcement.
AWS Lambda Improvements
We've got two announcements here.
Performance
The first announcement is better scaling performance. In the link below (which I set at the exact time in the session), Chris explains this news feature with an excellent graph, and I highly recommend the session.
Read the Lambda 12x faster scaling announcement.
Logging Improvements
The second announcement happened about a week before re:Invent and was related to structured logging support. This is excellent for those who write lean Lambda functions without external dependencies (such as a logger). Now, you can write your logs (with prints) in a JSON format and set the log level.
Read the Lambda advanced logging controls announcement.
EventBridge Pipes Logging Support
EventBridge Pipes is a promising service. However, until now, the lack of proper debug capabilities and error handling meant you needed to guess why your configuration or enrichment Lambda did not work. With this release, you can get logs and failure reasons (pushed to an S3 bucket if you wish, similar to Firehose's behavior) and debug your code. I can finally recommend EB pipes. Go ahead and give it a try.

Read the EventBridge Pipes logging support announcement.
If you wish to learn of a design that leverages EventBridge pipes to export logs from CW, read my CloudWatch log export blog post.
RedShift Serverless (Preview)
Ah, yes, the year of AI. I'm not too familiar with Amazon RedShift. However, this announcement is on the right path to making the service more self-managed. However, I wouldn't call it serverless just yet.
Amazon Redshift Serverless uses AI techniques to scale automatically with workload changes across all key dimensions—such as data volume changes, concurrent users, and query complexity—to meet and maintain your price performance targets
Read the RedShift Serverless AI-driven scaling announcement.
Amazon Aurora Limitless (Preview)
Amazon Aurora Limitless Database, which enables you to scale your Amazon Aurora clusters to millions of write transactions per second and manage petabytes of data. With this new capability, you can scale your relational database workloads on Aurora beyond the limits of a single Aurora writer instance without needing to create custom application logic or manage multiple databases.
As this feature is in preview, I'd wait before putting it in production anytime soon. However, on the surface, this can be huge for those who use Aurora and worry about writing custom scaling code.
Read the Amazon Aurora Limitless Database announcement.
Amazon Q (Preview)
Imagine having an AWS expert sitting next to you when you work. Imagine you can provide AI assistance to your employees or customers who knows your data and products at an expert level. This is the power and simplicity that Q strives to achieve.
Most importantly, I find this line in the article critical:
AWS never uses customers’ content from Amazon Q to train the underlying models. In other words, your company information remains secure and private.
The article provides several use cases for using Q which you can read in the Amazon Q preview announcement.
AWS AppComposer in VS Code
AppComposer comes to VS Code IDE. You can use AWS Application Composer's drag-and-drop interface to create an application design from scratch or import an existing application definition to edit it. It supports CloudFormation or SAM templates at the moment.
An elegant feature, you update your diagram, and IaC is added to your project, magic. Lots of potential here.
I hope there's CDK support coming in the future!
Read the AWS Application Composer IDE extension announcement.
Install the AWS Toolkit for VS Code.


